


IDEA 计算机视觉与机器人研究中心 (CVR,Computer Vision and Robotics) 发布 3B 参数多模态大语言模型 Rex-Omni,提升了模型对复杂语义和空间关系的理解水平,使目标检测能力实现跃进,为未来真正“懂语言”的视觉系统奠定基础。
Rex-Omni 的技术路径将为机器人视觉、自动驾驶、智能交互界面、工业检测等场景提供更具通用性、解释性与可迁移性的感知能力,推动 AI 感知从任务专用走向任务通用,成为下一代具备认知智能特征的视觉基础模型的重要原点。
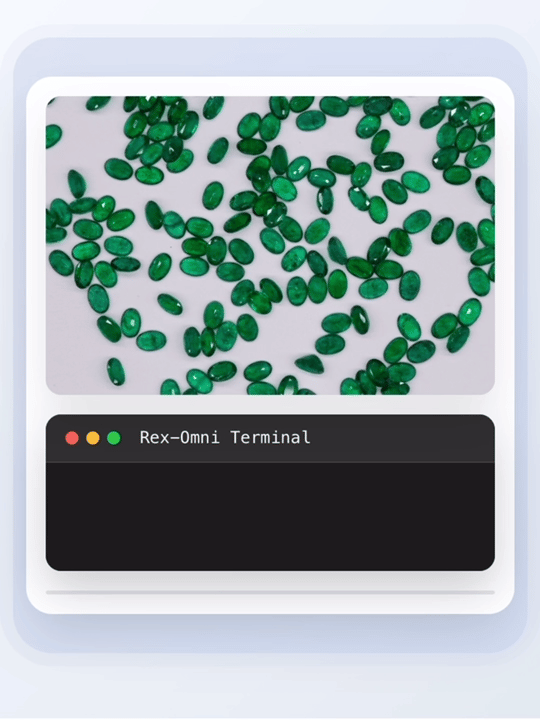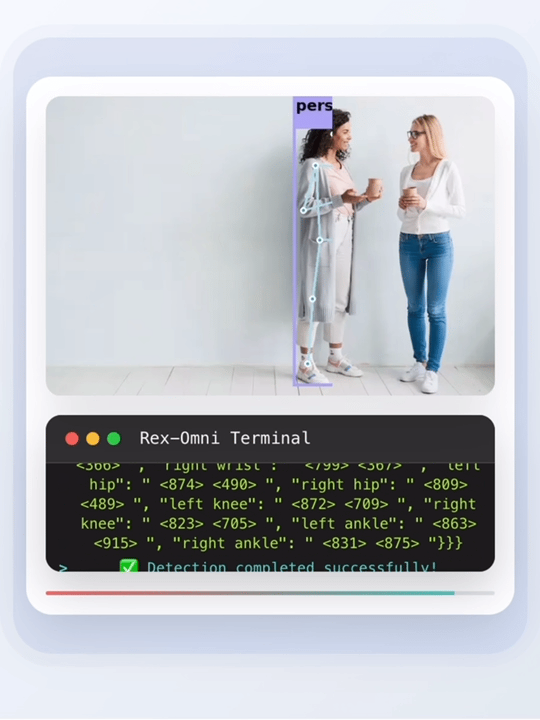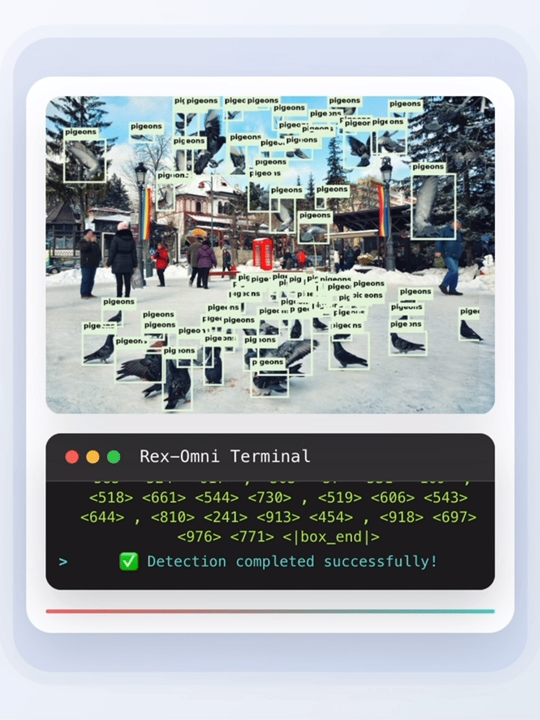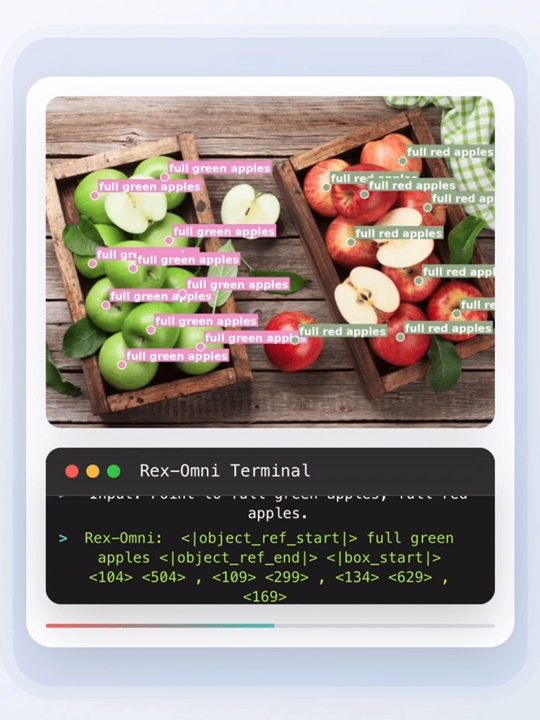
目标检测作为计算机视觉领域的关键技术,是人工智能从静态识别走向动态认知的基础能力支撑。
在人工智能技术发展中,目标检测推动 AI 视觉感知从 “被动接收图像信息” 向 “主动定位关键信息” 升级,使其更贴近人类视觉的 “定位 + 识别” 逻辑,助力 AI 感知向类人化迈进,为机器人抓取等场景中的 AI 决策提供了必要的位置信息依据。
现有目标检测方法中,传统回归模型定位精度高,但语言理解浅,无法处理复杂语义,例如在任务中仅能检测“苹果”却无法区分“红苹果”。
多模态大语言模型(MLLM)依托其底层大语言模型(LLM)的强大语言理解能力,为目标检测中提升高级语言理解提供了可行路径。
但在实际使用中,MLLM 的空间定位能力差,存在低召回率、坐标偏移、重复预测的问题,实际表现不如传统回归模型,背后原因源于模型采用分类问题理解和教师强制(teacher-forcing)训练策略。

如何在利用多模态大语言模型对高级语义的理解能力的同时提升其检测精度,成为目标检测研究的新课题。
三大核心设计
实现 MLLM 检测能力突破
Rex-Omni 研究团队通过三个核心设计,实现 MLLM 目标检测能力的新突破:
1. 任务构建(Task Formulation)
核心是给模型定一个 “通用规矩”,不管什么任务,都按同一个逻辑来学,大幅降低坐标学习复杂度、简化优化过程,同时提升空间表示效率。
具体来说,即将所有视觉感知任务统一到 “坐标预测框架” 下,即每个任务均被构建为 “生成坐标序列”。
例如,“指向任务” 预测 1 个点;“检测任务” 用 2 个点构成边界框;“多边形任务” 用 4 个及以上点表示目标轮廓;“关键点任务” 输出多个语义点。同时,采用 “量化坐标表示”—— 将每个坐标值映射到 1000 个离散 token(对应 0-999 的数值)。
2. 数据引擎(Data Engines)
为帮助模型学习 “1000 个量化坐标 token” 与 “像素级位置” 的映射关系,并稳健理解复杂自然语言表达,团队为 “定位、指代、指向” 任务设计了多个专用数据引擎。这些引擎生成高质量、语义丰富的视觉监督信号,用于坐标预测训练。
3. 训练流程(Training Pipelines)
采用两阶段训练范式,进行监督微调和基于 GRPO(Group-based Reward Policy Optimization) 的强化学习后训练。
第一阶段:在 2200 万数据上进行监督微调,教授模型基础坐标预测能力;
第二阶段:采用基于 GRPO [92] 的强化学习后训练,结合三个 “几何感知奖励函数”。该强化学习阶段实现两大目标:一是通过 “连续几何监督” 提升坐标预测精度;二是关键在于缓解 “初始 SFT 阶段教师引导特性” 导致的不良行为(如预测重复)。
强大泛化能力
小模型胜任多种感知任务
Rex-Omni 是一款用于目标检测的 3B 参数多模态大语言模型(MLLM),具备小而强的可落地性。
在多种感知任务中,Rex-Omni 均实现优异性能,包括目标检测、目标指代、视觉提示、GUI 定位、布局定位、OCR 识别、目标指向、关键点检测、空间指代等,且所有任务均通过 “直接预测坐标点” 实现。
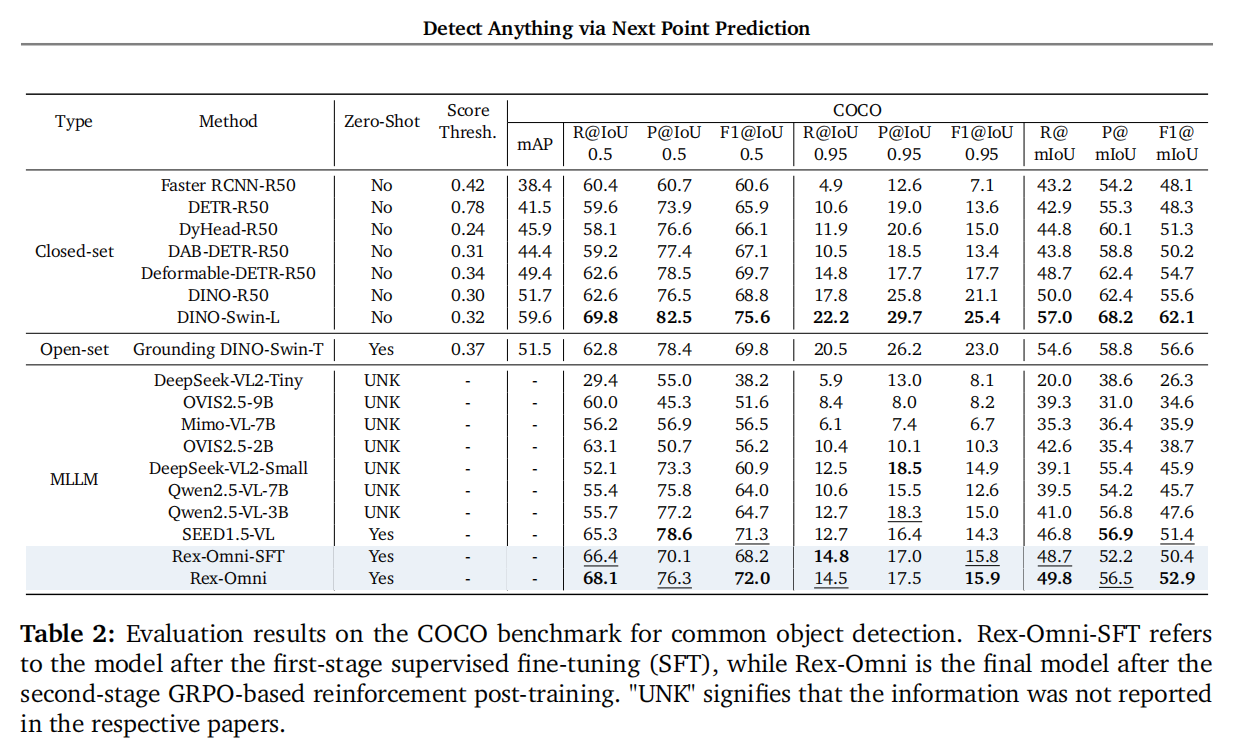
在权威的目标检测核心基准 COCO 测试中,Rex-Omni 在零样本设置下,F1 分数超过传统坐标回归模型和其他 MLLM,甚至超过为测试专门训练后的传统检测器 DINO-R50。
在长尾检测、指代表达理解、密集目标检测、GUI 定位、OCR 识别等多样化任务测试中,Rex-Omni 性能结果均优于传统检测器与其他 MLLM,检测结果接近真实标注(GT)。

上图为 Rex-Omni 与各模型的长尾场景检测结果

上图为 Rex-Omni 与各模型的密集场景检测结果
Rex-Omni 的能力将赋能多种场景应用,例如:
通过创新的任务构建、数据引擎和训练流程,Rex-Omni 解决了现有 MLLM 在目标检测中“语言强但定位弱”的痛点,提升了识别准确度。这项成果也证明, MLLM 具备定义下一代目标检测模型的巨大潜力,有望为视觉感知系统带来前所未有的通用性与 “真正懂语言” 的能力。
IDEA 计算机视觉与机器人研究中心 (CVR,Computer Vision and Robotics) 发布 3B 参数多模态大语言模型 Rex-Omni,提升了模型对复杂语义和空间关系的理解水平,使目标检测能力实现跃进,为未来真正“懂语言”的视觉系统奠定基础。
Rex-Omni 的技术路径将为机器人视觉、自动驾驶、智能交互界面、工业检测等场景提供更具通用性、解释性与可迁移性的感知能力,推动 AI 感知从任务专用走向任务通用,成为下一代具备认知智能特征的视觉基础模型的重要原点。
目标检测作为计算机视觉领域的关键技术,是人工智能从静态识别走向动态认知的基础能力支撑。
在人工智能技术发展中,目标检测推动 AI 视觉感知从 “被动接收图像信息” 向 “主动定位关键信息” 升级,使其更贴近人类视觉的 “定位 + 识别” 逻辑,助力 AI 感知向类人化迈进,为机器人抓取等场景中的 AI 决策提供了必要的位置信息依据。
现有目标检测方法中,传统回归模型定位精度高,但语言理解浅,无法处理复杂语义,例如在任务中仅能检测“苹果”却无法区分“红苹果”。
多模态大语言模型(MLLM)依托其底层大语言模型(LLM)的强大语言理解能力,为目标检测中提升高级语言理解提供了可行路径。
但在实际使用中,MLLM 的空间定位能力差,存在低召回率、坐标偏移、重复预测的问题,实际表现不如传统回归模型,背后原因源于模型采用分类问题理解和教师强制(teacher-forcing)训练策略。
如何在利用多模态大语言模型对高级语义的理解能力的同时提升其检测精度,成为目标检测研究的新课题。
三大核心设计
实现 MLLM 检测能力突破
Rex-Omni 研究团队通过三个核心设计,实现 MLLM 目标检测能力的新突破:
1. 任务构建(Task Formulation)
核心是给模型定一个 “通用规矩”,不管什么任务,都按同一个逻辑来学,大幅降低坐标学习复杂度、简化优化过程,同时提升空间表示效率。
具体来说,即将所有视觉感知任务统一到 “坐标预测框架” 下,即每个任务均被构建为 “生成坐标序列”。
例如,“指向任务” 预测 1 个点;“检测任务” 用 2 个点构成边界框;“多边形任务” 用 4 个及以上点表示目标轮廓;“关键点任务” 输出多个语义点。同时,采用 “量化坐标表示”—— 将每个坐标值映射到 1000 个离散 token(对应 0-999 的数值)。
2. 数据引擎(Data Engines)
为帮助模型学习 “1000 个量化坐标 token” 与 “像素级位置” 的映射关系,并稳健理解复杂自然语言表达,团队为 “定位、指代、指向” 任务设计了多个专用数据引擎。这些引擎生成高质量、语义丰富的视觉监督信号,用于坐标预测训练。
3. 训练流程(Training Pipelines)
采用两阶段训练范式,进行监督微调和基于 GRPO(Group-based Reward Policy Optimization) 的强化学习后训练。
第一阶段:在 2200 万数据上进行监督微调,教授模型基础坐标预测能力;
第二阶段:采用基于 GRPO [92] 的强化学习后训练,结合三个 “几何感知奖励函数”。该强化学习阶段实现两大目标:一是通过 “连续几何监督” 提升坐标预测精度;二是关键在于缓解 “初始 SFT 阶段教师引导特性” 导致的不良行为(如预测重复)。
强大泛化能力
小模型胜任多种感知任务
Rex-Omni 是一款用于目标检测的 3B 参数多模态大语言模型(MLLM),具备小而强的可落地性。
在多种感知任务中,Rex-Omni 均实现优异性能,包括目标检测、目标指代、视觉提示、GUI 定位、布局定位、OCR 识别、目标指向、关键点检测、空间指代等,且所有任务均通过 “直接预测坐标点” 实现。
在权威的目标检测核心基准 COCO 测试中,Rex-Omni 在零样本设置下,F1 分数超过传统坐标回归模型和其他 MLLM,甚至超过为测试专门训练后的传统检测器 DINO-R50。
在长尾检测、指代表达理解、密集目标检测、GUI 定位、OCR 识别等多样化任务测试中,Rex-Omni 性能结果均优于传统检测器与其他 MLLM,检测结果接近真实标注(GT)。
上图为 Rex-Omni 与各模型的长尾场景检测结果
上图为 Rex-Omni 与各模型的密集场景检测结果
Rex-Omni 的能力将赋能多种场景应用,例如:
通过创新的任务构建、数据引擎和训练流程,Rex-Omni 解决了现有 MLLM 在目标检测中“语言强但定位弱”的痛点,提升了识别准确度。这项成果也证明, MLLM 具备定义下一代目标检测模型的巨大潜力,有望为视觉感知系统带来前所未有的通用性与 “真正懂语言” 的能力。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

