



![]()
近日,由粤港澳大湾区数字经济研究院(IDEA 研究院)孵化的 AI 合成数据企业——数创弧光(深圳)科技有限公司(DataArc) 宣布,已于近期连续完成种子轮及种子+轮融资,投后估值达数亿元人民币。两轮融资分别由英诺天使和东方富海领投,君联资本(君科丹木)、数字未来、启迪之星等财务投资方,以及华为哈勃、深智城等产业资本共同参与。
数创弧光核心团队均来自 IDEA 研究院的科研序列,致力于系统性解决大模型面临的“数据荒”难题。CEO 江旭晖博士具备复合背景,以及多项国家自然科学基金重点项目及国家重点研发计划经验;CTO 徐铖晋博士曾入选华为“天才少年”计划,并担任 IDEA 金融大模型研发总负责人。此外,IDEA 研究院创院理事长沈向洋院士,与 IDEA 署理院长、首席科学家郭健教授,共同担任项目顾问,为公司发展提供顶层战略支持。
该项目从研究院内前沿的学术成果出发,以两篇论文为起点,在不到一年时间内,完成了从关键技术突破、系统工程搭建到商业化产品落地的全链条跨越,迅速构建起以高质量合成数据为核心的技术与产品体系,是 IDEA 研究院“研产投”一体化机制下,前沿 AI 技术实现快速产品化与市场验证的又一典型案例。
数创弧光将聚焦小语种、隐私敏感行业、小样本及长尾场景,通过可控、可解释的合成数据技术,填补真实数据难以获取、共享或覆盖的关键空白,并通过“国内深耕高价值场景,海外规模化复制”的路径,进一步探索与拓展海外市场机会。
当前,大模型的能力进化正面临一个核心瓶颈:互联网上可合法使用的高质量真实数据正逐渐被消耗殆尽,同时,在大量的隐私行业及长尾场景中,真实数据往往面临采集困难、标注昂贵、隐私合规严格的多重约束。传统依赖真实数据规模的训练路径已接近效能上限,“数据缺口”日益成为制约模型持续演进与产业深度落地的关键因素。
在这一背景下,合成数据从早期的辅助工具,逐渐演变为补齐结构性“数据缺口”的必要基础设施。这一转变已在全球领先科技公司中形成共识,微软、OpenAI、NVIDIA 等企业均已将合成数据用于模型训练。
随着产业发展的深入,合成数据赛道也迎来了政策窗口期。2025 年,发改委联合国家数据局发布《关于完善数据流通安全治理 更好促进数据要素市场化价值化的实施方案》,将合成数据明确纳入数据要素化的重要技术路径;与此同时,国务院印发的《国务院关于深入实施“人工智能+”行动的意见》在“加强数据供给创新”章节中提出,支持发展数据标注、数据合成等技术,培育数据处理和数据服务产业。相关政策文件的出台,标志着合成数据的技术价值被进一步提升至国家人工智能战略支撑层面,为产业发展提供了明确的政策导向。
高质量合成数据远非简单的数据扩充。其技术核心在于能否为模型提供具备任务针对性、逻辑一致性、事实准确性及可验证性的有效训练增量,“Make data LLM ready”。尤其在金融、工业等高合规要求的行业中,合成数据还需同时满足隐私保护、安全可控与流程可复现等多重要求,技术门槛极高。
数创弧光的技术体系并非单一算法,而是一套覆盖大模型训练全生命周期(包括继续预训练、有监督微调与强化学习微调等)的系统性工程方案。其核心创新在于基于“语境图谱”的知识驱动生成路径。该技术将碎片化的文档、项目、人员及业务知识进行深度结构化连接,构建出映射真实世界关系的动态知识网络。在此网络之上引导大模型生成的问答与对话数据,使合成数据在语义与逻辑层面保持一致性和可解释性,避免事实错误与内容漂移。
这一方法的核心优势在于其可扩展的多样性。它能够基于同一知识空间内覆盖不同任务、不同推理路径和多跳场景,有效扩展长尾与边缘案例,解决了传统合成数据容易重复、单一的问题。实验结果显示,其在复杂多跳问答任务中的准确率较主流方案提升 25.4%,同时将成本降低了 85.7%,带来数据 10-30 倍的高质量扩充。
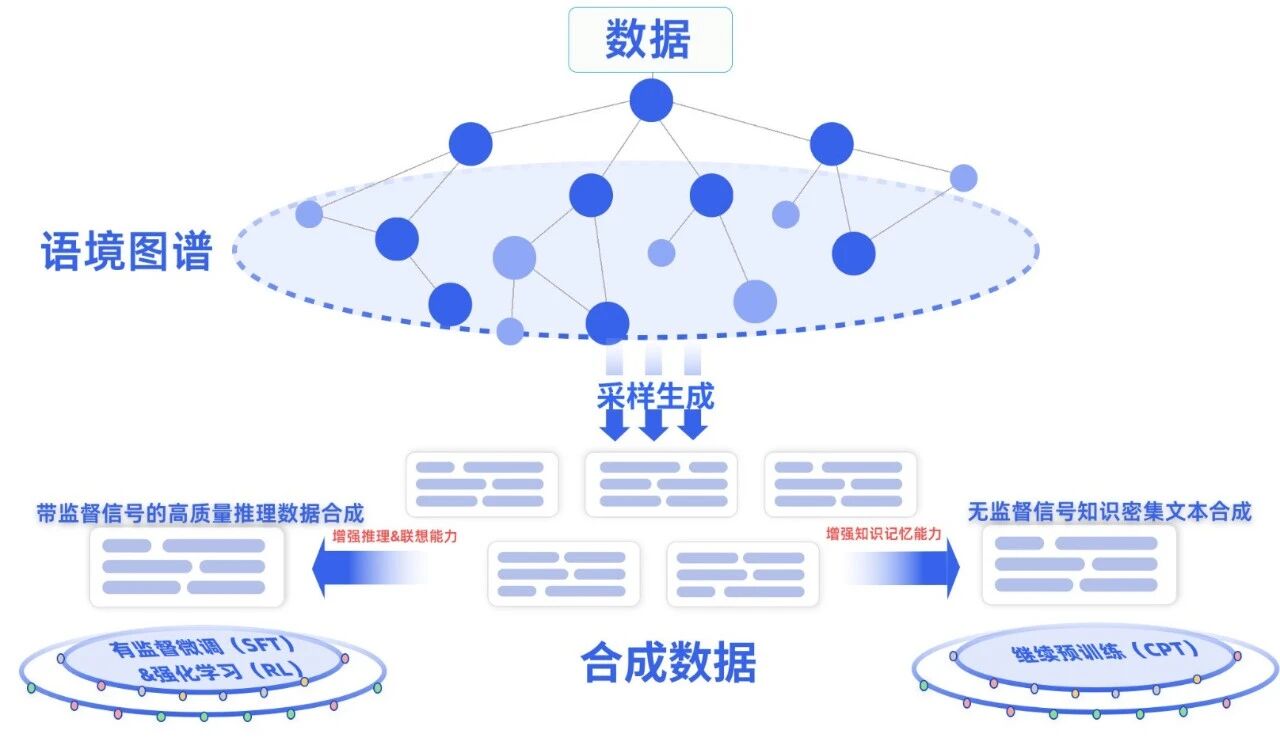
此外,数创弧光将数据筛选、质量评估与应用纳入统一工程体系,并通过合成数据加密训练技术,使模型在无需解密数据的情况下完成训练,确保生成与使用过程可控、可复现,从底层满足金融、工业等高合规行业对隐私与安全的要求。
值得一提的是,团队面向海外市场自研合成数据框架,结合文化与语言特点,为阿拉伯语、东南亚语系等低资源、高需求场景提供本地化数据供给和模型优化能力。在全球大模型赛道中,海外小语种市场蕴含独特价值:中东、非洲及东南亚等小语种地区用户群体庞大,但由于小语种语料极为稀缺,且存在文化、宗教和政策特殊性,传统大模型在此类语言环境下表现有限,单纯依靠翻译无法解决根本问题。数创弧光通过引入知识增强与深层语境理解的合成数据技术,在保持文化适配性的前提下,系统性扩充高质量语料规模,突破方言碎片化带来的数据限制,为模型训练提供可持续的有效增量。

2025 迪拜 GITEX-ENS,右二为 CEO 江旭晖
目前,数创弧光已推出两款核心标准产品,试图破解大模型数据痛点与企业知识管理难题,形成 “数据生成 – 知识应用” 协同:
SynData Platform 一站式合成数据平台,覆盖大模型训练全生命周期,可生成文本、表格、多模态数据,针对阿拉伯语等低资源语言打造文化适配框架,搭配加密训练技术与三重质量评估体系,数据质量接近人工标注水平,并已落地金融、工业等高复杂度垂直领域场景。
Living KB 企业知识库,聚焦企业知识规模化智能运营,依托语境图谱技术实现语义检索、图推理分析、自动化报告生成与动态更新,支持本地部署保障数据安全,适配金融、高端制造等行业合规查询、业务协同需求,大幅提升知识复用与业务响应效率。
沈向洋院士曾在 IDEA 大会上提出,“互联网 40 年积累的数据,好像就是为了这样一个 AI 时刻”。数据作为人工智能发展的“燃料”,其重要性早已显见。当真实数据红利见顶、合规与长尾场景数据成为模型进化瓶颈时,数创弧光将以高质量、可验证、合规的合成数据能力,系统性补齐大模型训练的结构性“数据缺口”,将独特的、难以被复制的跨语言文化理解壁垒落地到具体场景,把技术挑战转化为坚实的竞争护城河。
![]()
近日,由粤港澳大湾区数字经济研究院(IDEA 研究院)孵化的 AI 合成数据企业——数创弧光(深圳)科技有限公司(DataArc) 宣布,已于近期连续完成种子轮及种子+轮融资,投后估值达数亿元人民币。两轮融资分别由英诺天使和东方富海领投,君联资本(君科丹木)、数字未来、启迪之星等财务投资方,以及华为哈勃、深智城等产业资本共同参与。
数创弧光核心团队均来自 IDEA 研究院的科研序列,致力于系统性解决大模型面临的“数据荒”难题。CEO 江旭晖博士具备复合背景,以及多项国家自然科学基金重点项目及国家重点研发计划经验;CTO 徐铖晋博士曾入选华为“天才少年”计划,并担任 IDEA 金融大模型研发总负责人。此外,IDEA 研究院创院理事长沈向洋院士,与 IDEA 署理院长、首席科学家郭健教授,共同担任项目顾问,为公司发展提供顶层战略支持。
该项目从研究院内前沿的学术成果出发,以两篇论文为起点,在不到一年时间内,完成了从关键技术突破、系统工程搭建到商业化产品落地的全链条跨越,迅速构建起以高质量合成数据为核心的技术与产品体系,是 IDEA 研究院“研产投”一体化机制下,前沿 AI 技术实现快速产品化与市场验证的又一典型案例。
数创弧光将聚焦小语种、隐私敏感行业、小样本及长尾场景,通过可控、可解释的合成数据技术,填补真实数据难以获取、共享或覆盖的关键空白,并通过“国内深耕高价值场景,海外规模化复制”的路径,进一步探索与拓展海外市场机会。
当前,大模型的能力进化正面临一个核心瓶颈:互联网上可合法使用的高质量真实数据正逐渐被消耗殆尽,同时,在大量的隐私行业及长尾场景中,真实数据往往面临采集困难、标注昂贵、隐私合规严格的多重约束。传统依赖真实数据规模的训练路径已接近效能上限,“数据缺口”日益成为制约模型持续演进与产业深度落地的关键因素。
在这一背景下,合成数据从早期的辅助工具,逐渐演变为补齐结构性“数据缺口”的必要基础设施。这一转变已在全球领先科技公司中形成共识,微软、OpenAI、NVIDIA 等企业均已将合成数据用于模型训练。
随着产业发展的深入,合成数据赛道也迎来了政策窗口期。2025 年,发改委联合国家数据局发布《关于完善数据流通安全治理 更好促进数据要素市场化价值化的实施方案》,将合成数据明确纳入数据要素化的重要技术路径;与此同时,国务院印发的《国务院关于深入实施“人工智能+”行动的意见》在“加强数据供给创新”章节中提出,支持发展数据标注、数据合成等技术,培育数据处理和数据服务产业。相关政策文件的出台,标志着合成数据的技术价值被进一步提升至国家人工智能战略支撑层面,为产业发展提供了明确的政策导向。
高质量合成数据远非简单的数据扩充。其技术核心在于能否为模型提供具备任务针对性、逻辑一致性、事实准确性及可验证性的有效训练增量,“Make data LLM ready”。尤其在金融、工业等高合规要求的行业中,合成数据还需同时满足隐私保护、安全可控与流程可复现等多重要求,技术门槛极高。
数创弧光的技术体系并非单一算法,而是一套覆盖大模型训练全生命周期(包括继续预训练、有监督微调与强化学习微调等)的系统性工程方案。其核心创新在于基于“语境图谱”的知识驱动生成路径。该技术将碎片化的文档、项目、人员及业务知识进行深度结构化连接,构建出映射真实世界关系的动态知识网络。在此网络之上引导大模型生成的问答与对话数据,使合成数据在语义与逻辑层面保持一致性和可解释性,避免事实错误与内容漂移。
这一方法的核心优势在于其可扩展的多样性。它能够基于同一知识空间内覆盖不同任务、不同推理路径和多跳场景,有效扩展长尾与边缘案例,解决了传统合成数据容易重复、单一的问题。实验结果显示,其在复杂多跳问答任务中的准确率较主流方案提升 25.4%,同时将成本降低了 85.7%,带来数据 10-30 倍的高质量扩充。
此外,数创弧光将数据筛选、质量评估与应用纳入统一工程体系,并通过合成数据加密训练技术,使模型在无需解密数据的情况下完成训练,确保生成与使用过程可控、可复现,从底层满足金融、工业等高合规行业对隐私与安全的要求。
值得一提的是,团队面向海外市场自研合成数据框架,结合文化与语言特点,为阿拉伯语、东南亚语系等低资源、高需求场景提供本地化数据供给和模型优化能力。在全球大模型赛道中,海外小语种市场蕴含独特价值:中东、非洲及东南亚等小语种地区用户群体庞大,但由于小语种语料极为稀缺,且存在文化、宗教和政策特殊性,传统大模型在此类语言环境下表现有限,单纯依靠翻译无法解决根本问题。数创弧光通过引入知识增强与深层语境理解的合成数据技术,在保持文化适配性的前提下,系统性扩充高质量语料规模,突破方言碎片化带来的数据限制,为模型训练提供可持续的有效增量。
2025 迪拜 GITEX-ENS,右二为 CEO 江旭晖
目前,数创弧光已推出两款核心标准产品,试图破解大模型数据痛点与企业知识管理难题,形成 “数据生成 – 知识应用” 协同:
SynData Platform 一站式合成数据平台,覆盖大模型训练全生命周期,可生成文本、表格、多模态数据,针对阿拉伯语等低资源语言打造文化适配框架,搭配加密训练技术与三重质量评估体系,数据质量接近人工标注水平,并已落地金融、工业等高复杂度垂直领域场景。
Living KB 企业知识库,聚焦企业知识规模化智能运营,依托语境图谱技术实现语义检索、图推理分析、自动化报告生成与动态更新,支持本地部署保障数据安全,适配金融、高端制造等行业合规查询、业务协同需求,大幅提升知识复用与业务响应效率。
沈向洋院士曾在 IDEA 大会上提出,“互联网 40 年积累的数据,好像就是为了这样一个 AI 时刻”。数据作为人工智能发展的“燃料”,其重要性早已显见。当真实数据红利见顶、合规与长尾场景数据成为模型进化瓶颈时,数创弧光将以高质量、可验证、合规的合成数据能力,系统性补齐大模型训练的结构性“数据缺口”,将独特的、难以被复制的跨语言文化理解壁垒落地到具体场景,把技术挑战转化为坚实的竞争护城河。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

