


机器学习领域最重要的顶会之一 ICLR 2025 于今年四月在新加坡圆满落幕。今年大会共接收 11672 份投稿,较去年的投稿量增长超 50%。IDEA 研究院有 3 篇论文入选,内容覆盖多模态大语言模型、检索增强生成、三维人脸重建等技术,其中一篇获得 Oral 邀请(选中进入 Oral Presentation 口头报告的比例为投稿论文的 1.8%)。
本期 Paper Sparks 为大家详细介绍 IDEA 研究院入选 ICLR 2025 的亮点研究。
ICLR 论文主题一览
· ChartMoE: 入选 Oral。多样化训练 MoE,专为复杂图表理解与推理而设计的多模态大语言模型
· Think-on-Graph 2.0:基于知识图谱的混合 RAG 架构,无需额外训练,实现 LLMs 深度且可靠的推理
· TEASER:提取图像中的外观特征并标记,专注提升三维人脸表情重建的精度
01

自动图表理解对于内容理解和文档分析至关重要。然而当前的多模态大语言模型(Multimodal Large Language Models, MLLMs) 难以仅通过图表提供准确并可靠的数据和分析。为了解决这个问题,本文提出了多模态大语言模型 ChartMOE,通过多样化对齐训练和引入四元组数据,提升 MLLMs 使用 MoE 的 Sparse 结构在下游任务上的应用表现。
ChartMOE 通过多个对齐任务进行专家初始化,各专家专注不同图表特征,使模型具有显著的可解释性。同时构建了 ChartMoE-Align 数据集,其中包含约 900k 个图表-表格-JSON-代码四元组,这种对齐方式可以将 Chart 转译成更多样、全面的结构化文本格式,减少对应关系的模糊出错。通过与原生连接器相结合,采用高质量的知识学习进一步精细化 MoE 连接器和 LLM 参数,该 MLLM 可以多样化地初始化不同专家的参数,同时保持了模型在通用任务上的性能。

引入了一种基于专家混合(MoE)架构的连接器,并展示了排名第一的专家选择的可视化结果。ChartMoE 可以提取高度精确的值,并通过基于代码的交互实现灵活的图表编辑。
ChartMoE 在多个基准测试中大幅超越了之前的最先进模型,并且在图表问答、翻译和编辑等实际应用中表现出色。例如,ChartMoE 在图表问答(ChartQA)基准上的准确率从 80.48%提高到 84.64%。
随着对图表理解需求的不断增长和技术的不断进步,ChartMoE 的方法和架构有望为未来的多模态大语言模型的发展提供有价值的参考,推动图表理解和相关应用的进一步发展和创新。
本项工作获得今年的 Oral Presentation,由 IDEA 研究院、清华大学、北京大学和香港科技大学(广州)共同完成。
ICLR 2025 口头报告现场照片
02

传统方式的检索增强生成(RAG)大多数依赖文本相似度完成检索,缺少多步推理和发现深度关联信息的能力,难以在复杂问题中获取足够的有效信息。本文提出了一种基于知识图谱的混合 RAG 框架 Think-on-Graph 2.0(ToG2.0),它以紧密耦合的方式 (KG×Text) 从结构化和非结构化知识源中迭代检索信息,实现深度和可解释的推理。ToG2.0 无需训练,且可即插即用与多种 LLMs 兼容。
具体来说,ToG2.0 在初始化时促使 LLM 识别问题中的主题实体,从文档和知识图谱(KG)中捕捉与主题实体有关的上下文信息和关联实体,作为回答问题的线索,再进一步聚焦有效线索中内容完成解答,如果当前线索不足以回答问题,则围绕关联实体寻找新的问题线索。ToG2.0 在图谱检索和上下文检索之间交替进行,以搜索与问题相关的深入线索,使 LLMs 实现深度且可靠的推理。
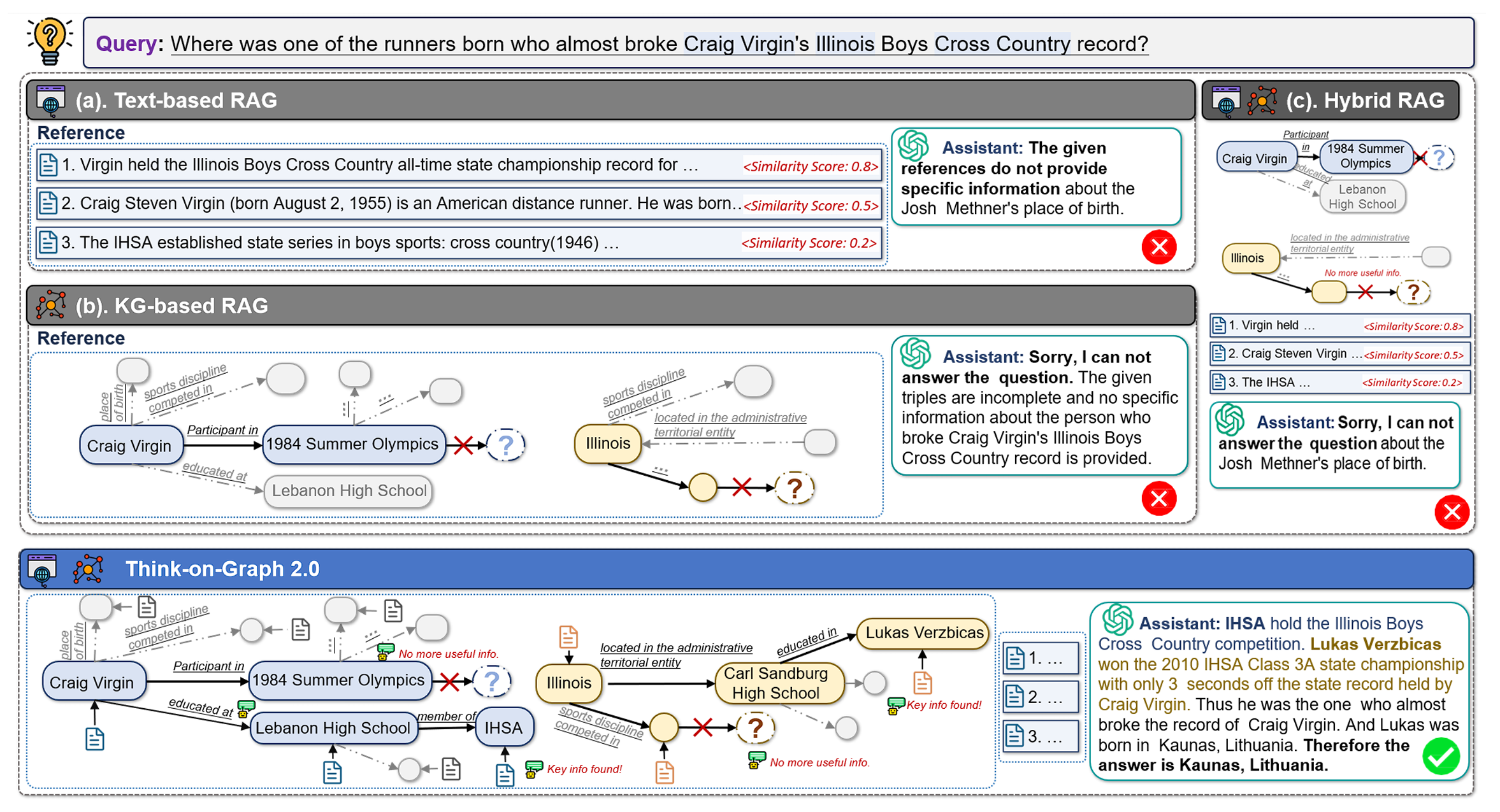
ToG2.0 工作流程的示例
实验表明 ToG2.0 在使用 GPT-3.5 中6 个知识密集型数据集的表现达到了 SOTA(State-of-the-art,最先进模型),并能够将较小模型(如 LLAMA-2-13B)的表现提升到与 GPT-3.5 直接推理相当的水平。本研究推动了 AI 在深度知识理解和推理领域的发展,模型在开放域问答和专业领域分析等方面具有广阔应用前景。
本项工作由 IDEA 研究院,中国人民大学高瓴人工智能学院、香港中文大学和香港科技大学共同完成。
03

单张自然图像的三维人脸重建是以人为中心的计算机视觉中的关键任务,但现有方法在细粒度表情捕捉方面仍有较大提升空间。本文提出了 TEASER(Token EnhAnced Spatial modeling for Expressions Reconstruction),通过混合表征(显式几何参数 + 隐式外观 Token) 和 Token 引导的神经渲染器,提升三维人脸表情重建的精度,解决了现有方法中自重建光度损失不足和微妙表情定位不准的问题。
TEASER 利用多尺度标记器从输入图像中提取复杂的面部外观特征,包括自遮挡阴影、眼镜、照明和各种肤色等信息,并将其压缩成一组”外观标记”(Token),提升生成的真实感。并结合神经渲染器,将这些 token 用作精确的几何引导,从而提高了表情重建的准确性,能够更好地处理复杂表情和细微动作。此外,通过引入损失函数,进一步增强几何精准度。

TEASER 通过估计用于三维人脸重建的混合参数,精确还原三维面部表情,并生成高保真的人脸图像。
TEASER 在 LRS3 和 HDTF 测试数据集上的定量与定性实验均显示出领先性能,不仅显著提升了表情重建质量,还具备良好的可解释性。这些 token 可广泛应用于高真实感人脸驱动、表情迁移和身份置换等下游任务。此外,TEASER 在视频级别的重建中也表现出更好的稳定性,具有更低的变形误差和闪烁水平。
这项研究为高精度、可控性强的人脸重建提供了新路径,未来可广泛应用于虚拟人、沉浸式交互、影视制作及远程会议等领域。随着技术发展,TEASER 有望推动情感计算与人机交互的深度融合,实现更真实自然的数字化人类表达。
本项工作由 IDEA 研究院和北京大学深圳研究生院共同完成。
机器学习领域最重要的顶会之一 ICLR 2025 于今年四月在新加坡圆满落幕。今年大会共接收 11672 份投稿,较去年的投稿量增长超 50%。IDEA 研究院有 3 篇论文入选,内容覆盖多模态大语言模型、检索增强生成、三维人脸重建等技术,其中一篇获得 Oral 邀请(选中进入 Oral Presentation 口头报告的比例为投稿论文的 1.8%)。
本期 Paper Sparks 为大家详细介绍 IDEA 研究院入选 ICLR 2025 的亮点研究。
ICLR 论文主题一览
· ChartMoE: 入选 Oral。多样化训练 MoE,专为复杂图表理解与推理而设计的多模态大语言模型
· Think-on-Graph 2.0:基于知识图谱的混合 RAG 架构,无需额外训练,实现 LLMs 深度且可靠的推理
· TEASER:提取图像中的外观特征并标记,专注提升三维人脸表情重建的精度
01
自动图表理解对于内容理解和文档分析至关重要。然而当前的多模态大语言模型(Multimodal Large Language Models, MLLMs) 难以仅通过图表提供准确并可靠的数据和分析。为了解决这个问题,本文提出了多模态大语言模型 ChartMOE,通过多样化对齐训练和引入四元组数据,提升 MLLMs 使用 MoE 的 Sparse 结构在下游任务上的应用表现。
ChartMOE 通过多个对齐任务进行专家初始化,各专家专注不同图表特征,使模型具有显著的可解释性。同时构建了 ChartMoE-Align 数据集,其中包含约 900k 个图表-表格-JSON-代码四元组,这种对齐方式可以将 Chart 转译成更多样、全面的结构化文本格式,减少对应关系的模糊出错。通过与原生连接器相结合,采用高质量的知识学习进一步精细化 MoE 连接器和 LLM 参数,该 MLLM 可以多样化地初始化不同专家的参数,同时保持了模型在通用任务上的性能。
引入了一种基于专家混合(MoE)架构的连接器,并展示了排名第一的专家选择的可视化结果。ChartMoE 可以提取高度精确的值,并通过基于代码的交互实现灵活的图表编辑。
ChartMoE 在多个基准测试中大幅超越了之前的最先进模型,并且在图表问答、翻译和编辑等实际应用中表现出色。例如,ChartMoE 在图表问答(ChartQA)基准上的准确率从 80.48%提高到 84.64%。
随着对图表理解需求的不断增长和技术的不断进步,ChartMoE 的方法和架构有望为未来的多模态大语言模型的发展提供有价值的参考,推动图表理解和相关应用的进一步发展和创新。
本项工作获得今年的 Oral Presentation,由 IDEA 研究院、清华大学、北京大学和香港科技大学(广州)共同完成。
ICLR 2025 口头报告现场照片
02
传统方式的检索增强生成(RAG)大多数依赖文本相似度完成检索,缺少多步推理和发现深度关联信息的能力,难以在复杂问题中获取足够的有效信息。本文提出了一种基于知识图谱的混合 RAG 框架 Think-on-Graph 2.0(ToG2.0),它以紧密耦合的方式 (KG×Text) 从结构化和非结构化知识源中迭代检索信息,实现深度和可解释的推理。ToG2.0 无需训练,且可即插即用与多种 LLMs 兼容。
具体来说,ToG2.0 在初始化时促使 LLM 识别问题中的主题实体,从文档和知识图谱(KG)中捕捉与主题实体有关的上下文信息和关联实体,作为回答问题的线索,再进一步聚焦有效线索中内容完成解答,如果当前线索不足以回答问题,则围绕关联实体寻找新的问题线索。ToG2.0 在图谱检索和上下文检索之间交替进行,以搜索与问题相关的深入线索,使 LLMs 实现深度且可靠的推理。
ToG2.0 工作流程的示例
实验表明 ToG2.0 在使用 GPT-3.5 中6 个知识密集型数据集的表现达到了 SOTA(State-of-the-art,最先进模型),并能够将较小模型(如 LLAMA-2-13B)的表现提升到与 GPT-3.5 直接推理相当的水平。本研究推动了 AI 在深度知识理解和推理领域的发展,模型在开放域问答和专业领域分析等方面具有广阔应用前景。
本项工作由 IDEA 研究院,中国人民大学高瓴人工智能学院、香港中文大学和香港科技大学共同完成。
03
单张自然图像的三维人脸重建是以人为中心的计算机视觉中的关键任务,但现有方法在细粒度表情捕捉方面仍有较大提升空间。本文提出了 TEASER(Token EnhAnced Spatial modeling for Expressions Reconstruction),通过混合表征(显式几何参数 + 隐式外观 Token) 和 Token 引导的神经渲染器,提升三维人脸表情重建的精度,解决了现有方法中自重建光度损失不足和微妙表情定位不准的问题。
TEASER 利用多尺度标记器从输入图像中提取复杂的面部外观特征,包括自遮挡阴影、眼镜、照明和各种肤色等信息,并将其压缩成一组”外观标记”(Token),提升生成的真实感。并结合神经渲染器,将这些 token 用作精确的几何引导,从而提高了表情重建的准确性,能够更好地处理复杂表情和细微动作。此外,通过引入损失函数,进一步增强几何精准度。
TEASER 通过估计用于三维人脸重建的混合参数,精确还原三维面部表情,并生成高保真的人脸图像。
TEASER 在 LRS3 和 HDTF 测试数据集上的定量与定性实验均显示出领先性能,不仅显著提升了表情重建质量,还具备良好的可解释性。这些 token 可广泛应用于高真实感人脸驱动、表情迁移和身份置换等下游任务。此外,TEASER 在视频级别的重建中也表现出更好的稳定性,具有更低的变形误差和闪烁水平。
这项研究为高精度、可控性强的人脸重建提供了新路径,未来可广泛应用于虚拟人、沉浸式交互、影视制作及远程会议等领域。随着技术发展,TEASER 有望推动情感计算与人机交互的深度融合,实现更真实自然的数字化人类表达。
本项工作由 IDEA 研究院和北京大学深圳研究生院共同完成。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

