


IDEA 计算机视觉与机器人研究中心(CVR, Computer Vision and Robotics)张磊团队发布全新高性能 3D 实例分割框架 SegDINO3D。
该框架引入成熟 2D 检测模型的能力,开创性地使用通过图像级(全局场景特征)与物体级(局部实例特征)的双层级融合范式,基于 2D 信息增强对 3D 场景内的空间结构、物体尺度关系与实例边界等信息的理解,在大幅提升 3D 实例分割检测精度的同时,显著加快模型训练收敛速度。
SegDINO3D 在 ScanNetv2 与 ScanNet200 等主流基准数据集上取得 SOTA(State-of-the-Art),在更具挑战性、拥有更多长尾类别的 ScanNet200 benchmark 上实现了性能的巨大飞跃,相较于之前的方法,在 validation 和 hidden test sets 上分别提升了 + 8.6mAP 和 + 6.8mAP。
SegDINO3D 的技术突破,不仅极大地缓解视觉模型 3D 数据稀缺的困境,为空间智能赋予了“高精度、高性价比”的三维环境理解能力,推动空间智能与具身智能从 “感知可用” 迈向 “决策可靠”,也为更丰富的 3D 感知场景带来兼具高性能与实用性的可落地解决方案,其应用价值可辐射至自主机器人、自动驾驶、数字孪生等多个高价值产业赛道,为相关领域的技术升级与产业落地注入全新动力。
3D 实例分割作为计算机视觉领域让 AI 感知物理世界的核心技术,在自动驾驶、机器人交互、数字孪生构建等关键领域发挥着不可替代的作用,其核心目标是精准检测并分割 3D 场景中的每个物体实例,为下游任务提供可靠的环境理解基础。
当前,该领域的主流方案多采用 Transformer-based 编码器 – 解码器架构,仅以 3D 点云作为输入,通过 3D 编码器提取空间特征,再由解码器完成物体实例预测。
尽管技术持续发展,3D 实例分割领域仍长期面临两大核心痛点:一是 3D 训练数据(点云)的采集与标注成本极高,其数量和类别丰富度远不及海量易得的 2D 图像数据,这一差距严重限制了模型在复杂场景(尤其是长尾类别物体)中的泛化能力;二是 2D 特征在向 3D 空间迁移时易出现语义退化,即便借助 3D 编码器进行处理,也难以完全保留其原本强大的判别能力。
近年来已有研究尝试引入 2D 先验知识辅助 3D 感知,但在 2D 信息的有效利用上仍存在明显局限,比如:不少方法仅直接复用 2D 模型输出的 mask 结果,完全忽略了中间产生的丰富 2D 语义特征;或者为每个 3D 点从孤立的 2D 特征图中提取特征,却缺乏全局 3D 上下文融合,无法保证不同视角下实例的一致性。还有一部分方法是通过 3D 编码器对孤立 2D 特征进行全局编码,但受限于 3D 训练数据规模,最终仍会导致 2D 特征退化,难以发挥其真正价值。
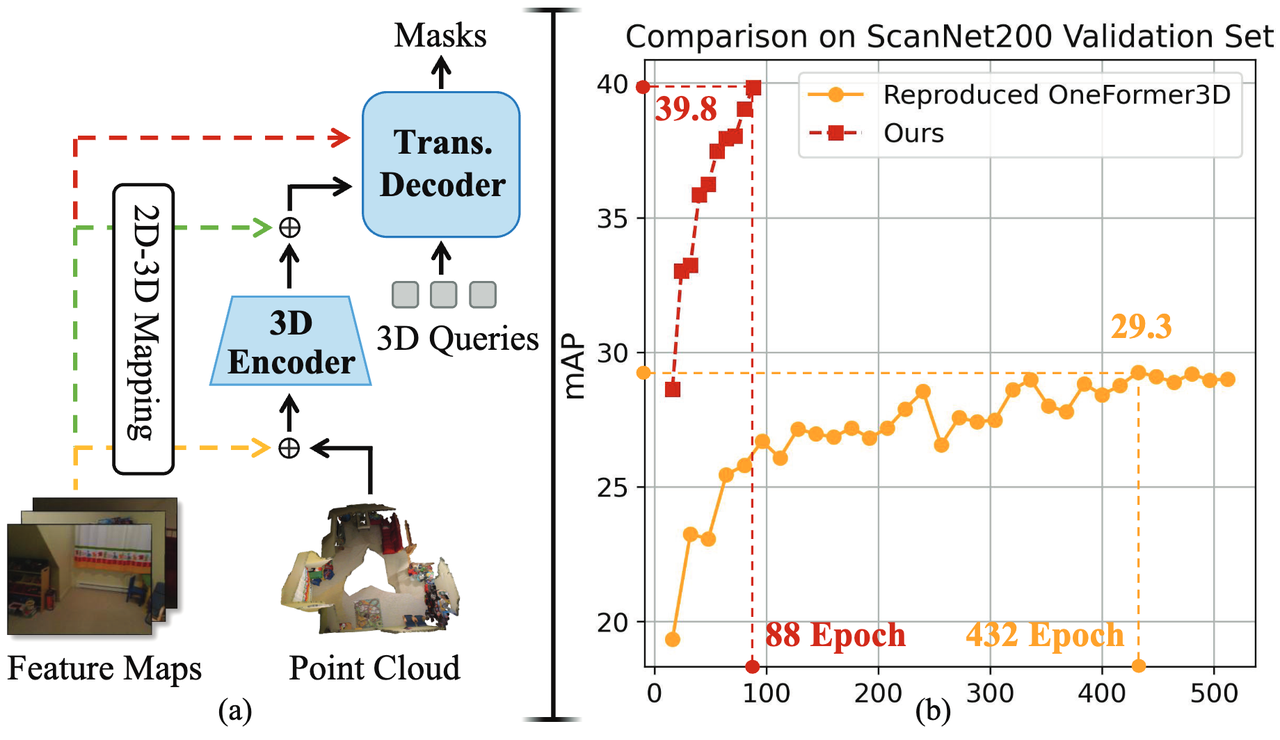
图 1 当前方法使用 2D 先验知识辅助 3D 感知的局限
针对上述问题,SegDINO3D 研究团队提出了创新性的 3D 实例分割框架 SegDINO3D,核心思路是通过编码器 – 解码器的协同设计,实现图像级(Image-Level)与物体级(Object-Level)双层级 2D 特征的全流程高效复用。在编码器阶段引入经全局增强的 2D 特征,在解码器阶段通过特殊设计保留其语义辨别能力,既解决了孤立 2D 特征的空间一致性问题,又避免了语义退化。此外,SegDINO3D 创新性地提出距离感知跨注意力(DACA-2D)与 3D 框调制跨注意力(BMCA-3D)两大核心模块,大幅提升特征匹配精度与计算效率。
实验验证表明,该框架不仅使训练收敛速度显著提升,更在 ScanNetv2 与 ScanNet200 等主流基准数据集上取得 SOTA(State-of-the-Art)性能,尤其在拥有更丰富长尾类别而更具挑战性的 ScanNet200 基准数据集上,验证集与隐藏测试集的 mAP 指标分别实现 +8.6mAP 与 +6.8mAP 的大幅跃升,为复杂场景下的 3D 实例分割提供了全新的高性能解决方案。
通过双层级 2D 特征融合与双注意力机制的核心创新,SegDINO3D 突破了 3D 训练数据稀缺与 2D 特征 3D 退化的核心瓶颈,为产业领域提供了高性能的 3D 感知解决方案,加速 3D 实例分割的产业落地与场景拓展,其应用场景覆盖多个高价值产业赛道:
(1)自主机器人与自动驾驶:凭借高精度的长尾类别分割能力与实时计算效率,SegDINO3D 可赋能服务机器人的室内导航与物体抓取,以及自动驾驶车辆的复杂路况感知,提升机器人与车辆对小目标、异形物体的识别精度。
(2)AR/VR 与数字孪生:在虚实融合场景中,该方法可快速完成真实环境的 3D 实例分割,为虚拟物体的精准放置与物理交互提供底层支撑;同时,在工业数字孪生构建中,能大幅降低 3D 模型标注成本,加速工厂、楼宇等场景的数字化建模。
(3)医疗影像分析:通过适配医学 3D 扫描数据(如 CT、MRI),SegDINO3D 可辅助医生精准分割肿瘤、器官等解剖结构,尤其在小病灶与不规则组织的识别上具备显著优势,为精准医疗提供技术支持。
(4)建筑与施工监测:利用 3D 扫描结合 SegDINO3D 的分割能力,可实现施工进度的自动化追踪与建筑缺陷检测,提升工程质量管控效率。
此外,它还为空间智能赋予了 “高精度、高性价比” 的三维环境理解能力,破解了以往空间建模数据依赖重、部署成本高的痛点;同时让具身智能在动态场景中具备更精准的障碍物识别、更灵活的目标交互能力,推动空间智能与具身智能从 “感知可用” 迈向 “决策可靠”。
实现方法
SegDINO3D 的整体框架如下图所示,核心在于 Encoder 和 Decoder 中对 2D 特征(SegDINO3D 研究团队选择了 DINO-X 与 Grounding DINO 等 2D 检测模型来提供 2D 特征)的合理利用,以及 3D 框调制交叉注意力(Box-Modulated Cross-Attention)机制。具体如下:
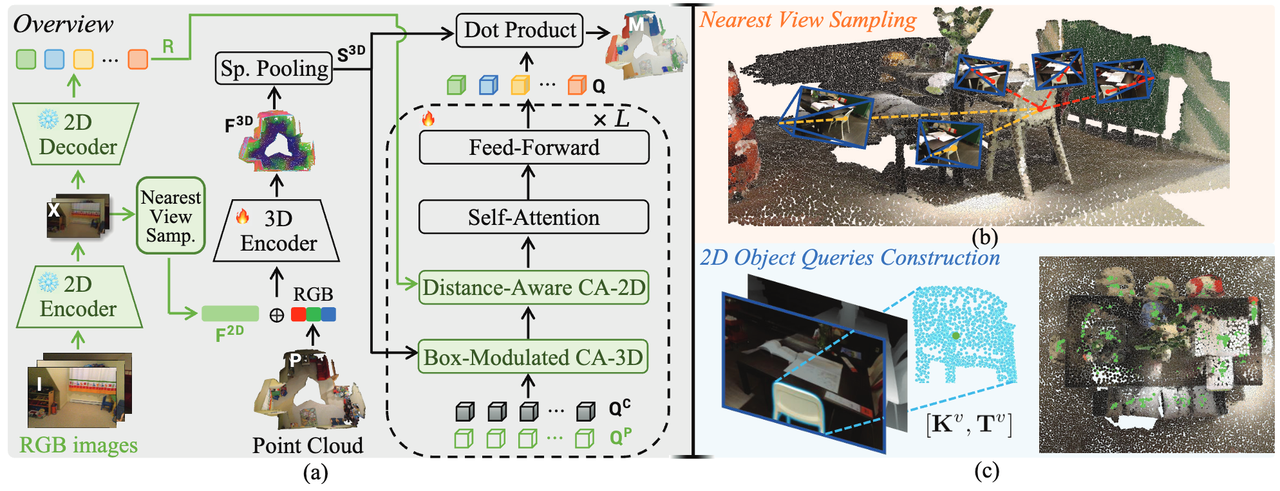
图 2 SegDINO3D 的整体框架
(1)Encoder 阶段:图像级特征增强(Image-Level)
传统的点云特征往往语义信息不足,SegDINO3D 研究团队提出通过最近视点采样(Nearest View Sampling)策略来利用 2D 图像的语义信息增强原始 3D 点云。
具体而言,对于每个 3D 点,并不盲目聚合所有视角的图片特征,而是只选取距离相机最近的 k 个视角图片,降低计算量的同时提取的特征也更加清晰可靠。之后再使用 3D Encoder 进行全局上下文融合,从而解决孤立视角之间缺乏 3D 空间一致性的问题。
(2)Decoder 阶段:物体级特征注入(Object-Level)
经过 3D Encoder 后,2D 特征的语义信息可能有所损失,因此 SegDINO3D 研究团队提出在 Decoder 阶段再次利用原始的强大 2D 语义特征。由于把成百上千张图片的特征图都存入显存以直接使用会引入巨大的计算开销,因此 SegDINO3D 框架选择直接利用 2D 检测模型输出的 2D queries,并将其视为物体级的高效压缩表示。
具体而言,SegDINO3D 先利用 2D 检测模型处理输入的图片并检测其中所有要求类别的物体,并设置阈值保留输出的高置信度的 queries。之后利用深度信息与相机参数将它们投影到 3D 空间,并通过 FPS 降采样保留 2048 个。
其后,3D query 直接通过距离感知交叉注意力(Distance-Aware Cross-Attention) 机制从投影到 3D 空间的 2D queries 中提取信息,该过程中会使用一个基于空间距离的注意力掩码,确保每个 3D query 只关注附近的 2D queries,减少计算量的同时实现了更准确的特征提取。
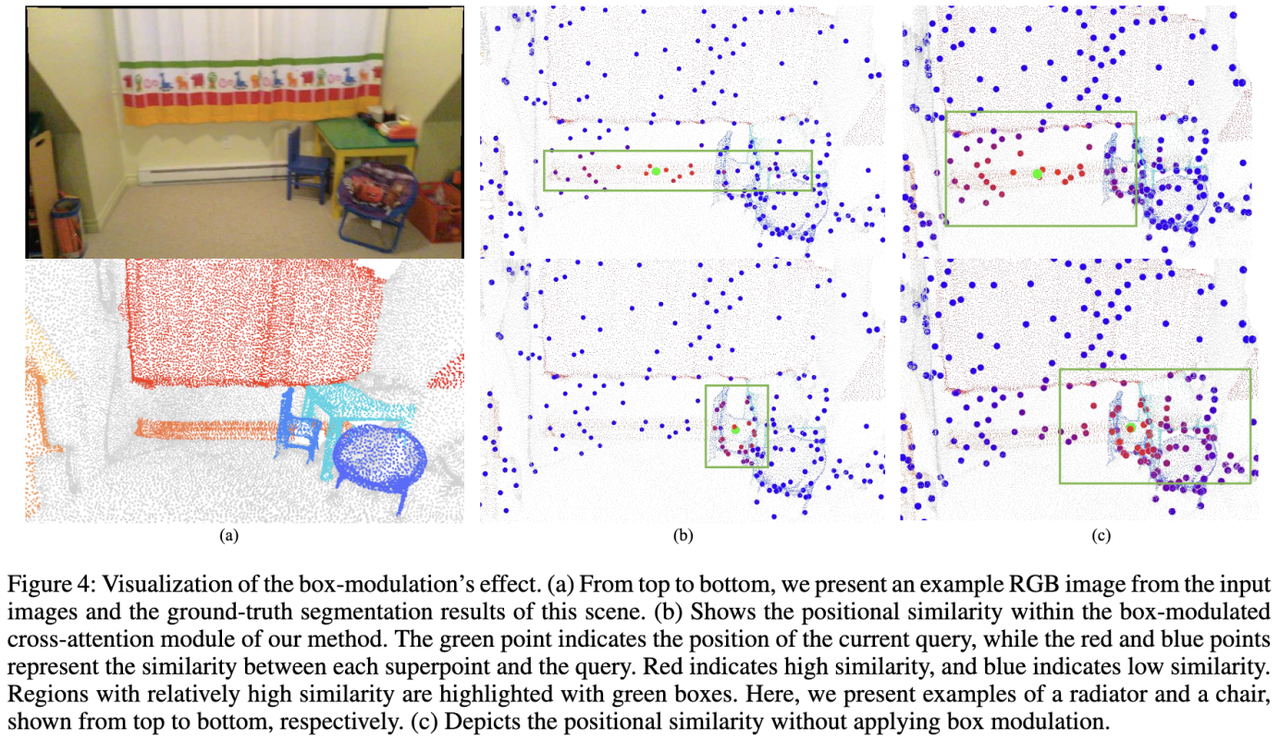
(3)3D 框调制交叉注意力(Box-Modulated Cross-Attention)机制
以往的 3D 实例分割模型通常使用掩码注意力(Mask-Attention)来与场景中的信息进行交互,但此时仅依赖于内容相似度而忽略了位置关系。最近有一些方法在此基础上引入了位置编码,但他们都是各向同性的(像一个球),无法捕捉到不同物体的尺度差异。
受到 2D 检测模型(DAB-DETR,DINO)的启发,SegDINO3D 研究团队将 3D query 建模为轴对齐的 3D 框(axis-aligned 3D boxes),并引入了辅助任务,要求每一个 3D query 估计物体的 3D 框。然后,我们使用估计的 3D 框来调制 positional attention map,使得 3D queries 能够根据物体的尺寸自适应地调制 attention 范围,从而更准确地从环境特征中提取信息。
实验指标和可视化
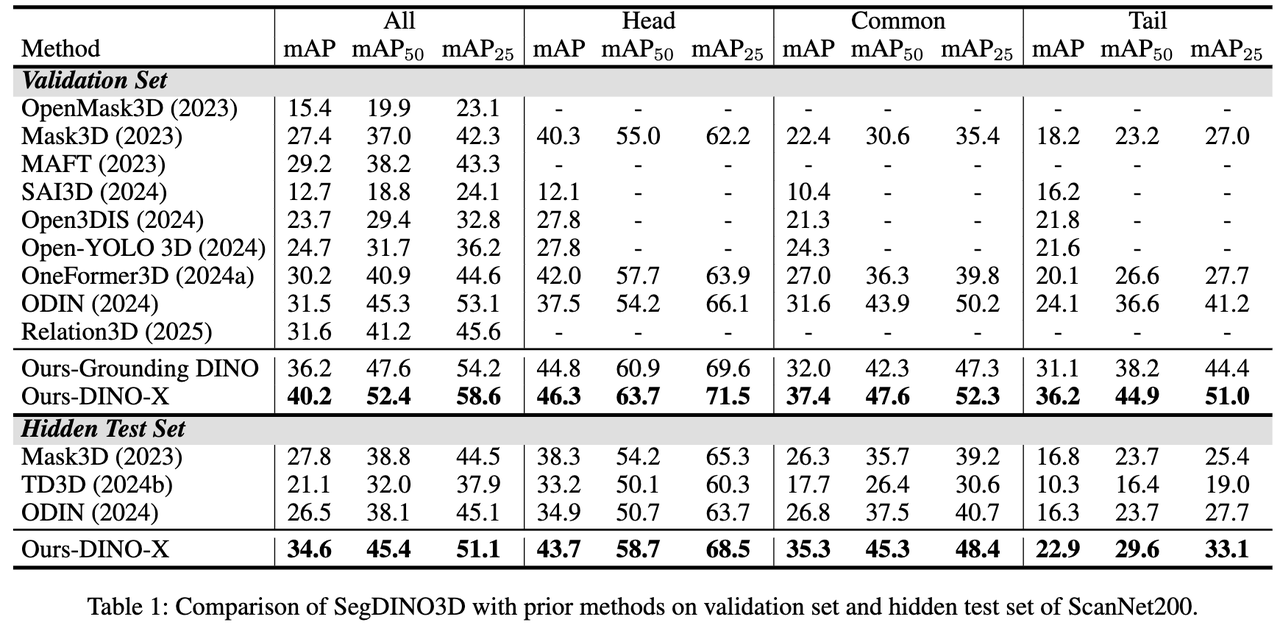
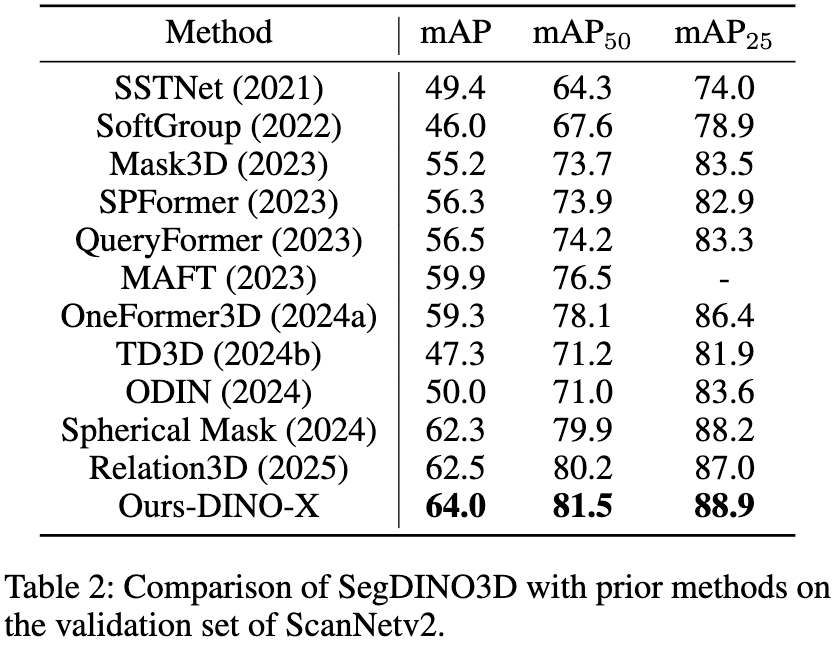
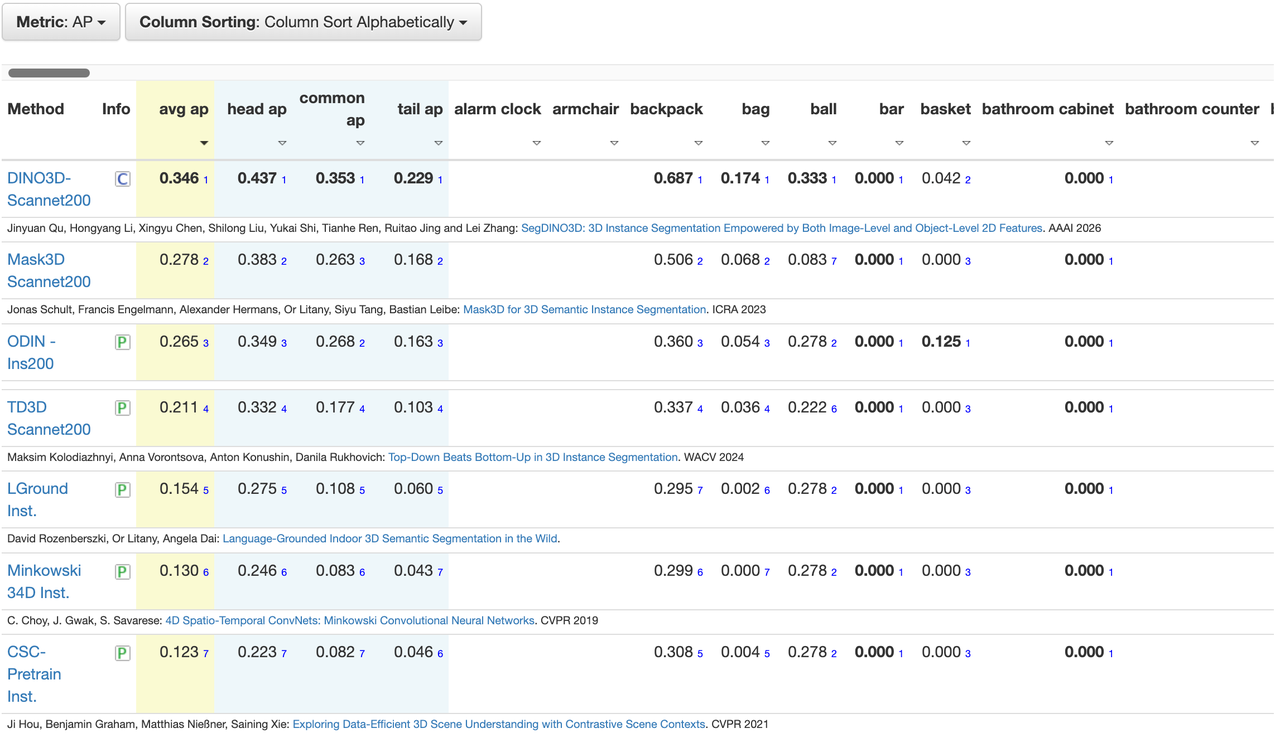
SegDINO3D 在 ScanNetv2 和 ScanNet200 等主流 benchmark 上都取得了 SOTA 表现,尤其是在更具挑战性,拥有更多长尾类别的 ScanNet200 benchmark 上实现了性能的巨大飞跃,相较于之前的方法,在 validation 和 hidden test sets 上分别提升了 +8.6mAP 和 +6.8mAP。
ScanNet200 Benchmark:
ScanNetv2 Validation Set:
Main Ablation:

ScanNet200 Hidden Test:
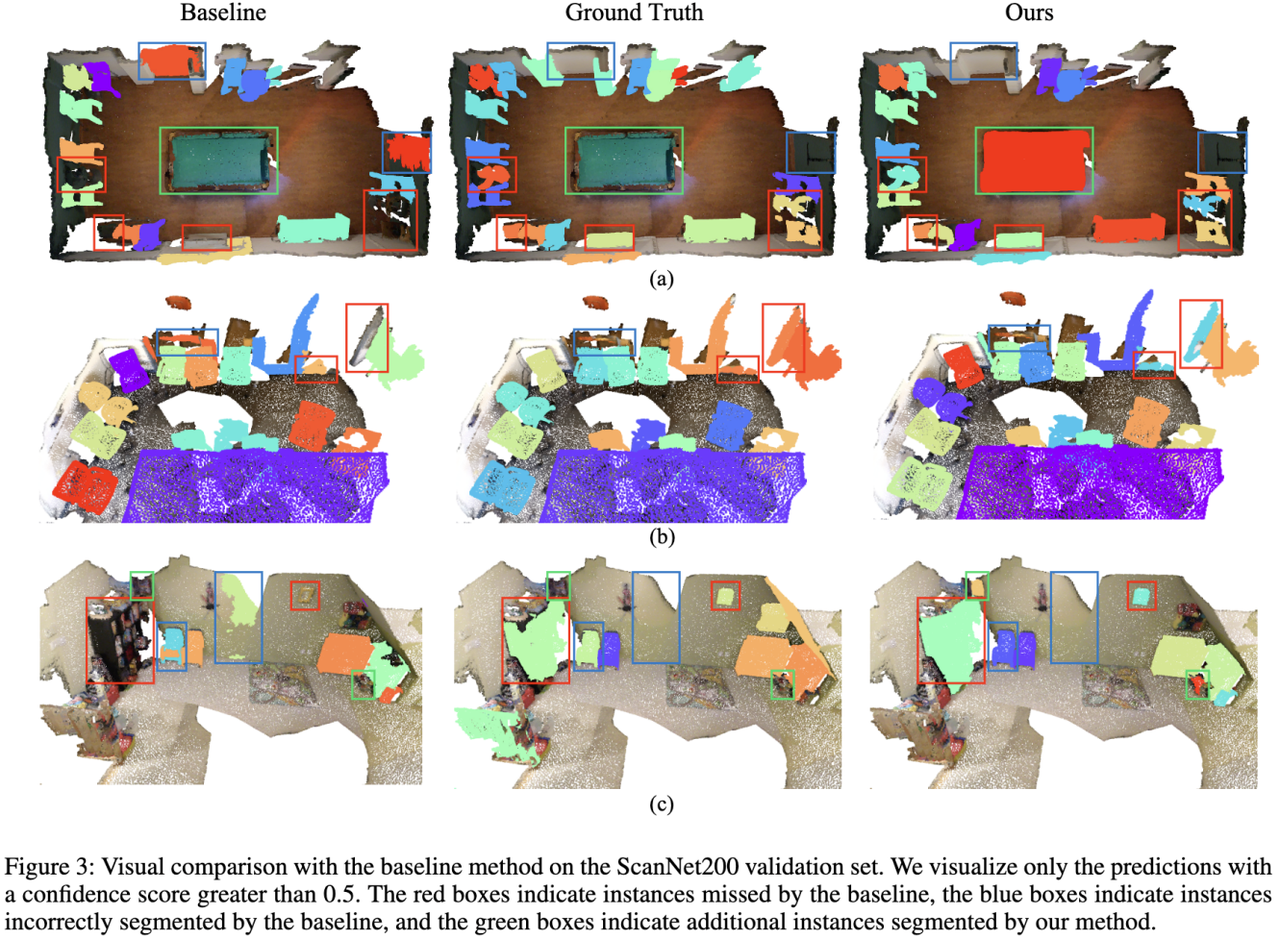
SegDINO3D 的可视化效果(Qualitative Performance):
(1)与以往方法的对比
(2)3D 框调制交叉注意力(Box-Modulated Cross-Attention)可视化
(3)可视化估计的 mask 与 bounding box

IDEA 计算机视觉与机器人研究中心(CVR, Computer Vision and Robotics)张磊团队发布全新高性能 3D 实例分割框架 SegDINO3D。
该框架引入成熟 2D 检测模型的能力,开创性地使用通过图像级(全局场景特征)与物体级(局部实例特征)的双层级融合范式,基于 2D 信息增强对 3D 场景内的空间结构、物体尺度关系与实例边界等信息的理解,在大幅提升 3D 实例分割检测精度的同时,显著加快模型训练收敛速度。
SegDINO3D 在 ScanNetv2 与 ScanNet200 等主流基准数据集上取得 SOTA(State-of-the-Art),在更具挑战性、拥有更多长尾类别的 ScanNet200 benchmark 上实现了性能的巨大飞跃,相较于之前的方法,在 validation 和 hidden test sets 上分别提升了 + 8.6mAP 和 + 6.8mAP。
SegDINO3D 的技术突破,不仅极大地缓解视觉模型 3D 数据稀缺的困境,为空间智能赋予了“高精度、高性价比”的三维环境理解能力,推动空间智能与具身智能从 “感知可用” 迈向 “决策可靠”,也为更丰富的 3D 感知场景带来兼具高性能与实用性的可落地解决方案,其应用价值可辐射至自主机器人、自动驾驶、数字孪生等多个高价值产业赛道,为相关领域的技术升级与产业落地注入全新动力。
3D 实例分割作为计算机视觉领域让 AI 感知物理世界的核心技术,在自动驾驶、机器人交互、数字孪生构建等关键领域发挥着不可替代的作用,其核心目标是精准检测并分割 3D 场景中的每个物体实例,为下游任务提供可靠的环境理解基础。
当前,该领域的主流方案多采用 Transformer-based 编码器 – 解码器架构,仅以 3D 点云作为输入,通过 3D 编码器提取空间特征,再由解码器完成物体实例预测。
尽管技术持续发展,3D 实例分割领域仍长期面临两大核心痛点:一是 3D 训练数据(点云)的采集与标注成本极高,其数量和类别丰富度远不及海量易得的 2D 图像数据,这一差距严重限制了模型在复杂场景(尤其是长尾类别物体)中的泛化能力;二是 2D 特征在向 3D 空间迁移时易出现语义退化,即便借助 3D 编码器进行处理,也难以完全保留其原本强大的判别能力。
近年来已有研究尝试引入 2D 先验知识辅助 3D 感知,但在 2D 信息的有效利用上仍存在明显局限,比如:不少方法仅直接复用 2D 模型输出的 mask 结果,完全忽略了中间产生的丰富 2D 语义特征;或者为每个 3D 点从孤立的 2D 特征图中提取特征,却缺乏全局 3D 上下文融合,无法保证不同视角下实例的一致性。还有一部分方法是通过 3D 编码器对孤立 2D 特征进行全局编码,但受限于 3D 训练数据规模,最终仍会导致 2D 特征退化,难以发挥其真正价值。
图 1 当前方法使用 2D 先验知识辅助 3D 感知的局限
针对上述问题,SegDINO3D 研究团队提出了创新性的 3D 实例分割框架 SegDINO3D,核心思路是通过编码器 – 解码器的协同设计,实现图像级(Image-Level)与物体级(Object-Level)双层级 2D 特征的全流程高效复用。在编码器阶段引入经全局增强的 2D 特征,在解码器阶段通过特殊设计保留其语义辨别能力,既解决了孤立 2D 特征的空间一致性问题,又避免了语义退化。此外,SegDINO3D 创新性地提出距离感知跨注意力(DACA-2D)与 3D 框调制跨注意力(BMCA-3D)两大核心模块,大幅提升特征匹配精度与计算效率。
实验验证表明,该框架不仅使训练收敛速度显著提升,更在 ScanNetv2 与 ScanNet200 等主流基准数据集上取得 SOTA(State-of-the-Art)性能,尤其在拥有更丰富长尾类别而更具挑战性的 ScanNet200 基准数据集上,验证集与隐藏测试集的 mAP 指标分别实现 +8.6mAP 与 +6.8mAP 的大幅跃升,为复杂场景下的 3D 实例分割提供了全新的高性能解决方案。
通过双层级 2D 特征融合与双注意力机制的核心创新,SegDINO3D 突破了 3D 训练数据稀缺与 2D 特征 3D 退化的核心瓶颈,为产业领域提供了高性能的 3D 感知解决方案,加速 3D 实例分割的产业落地与场景拓展,其应用场景覆盖多个高价值产业赛道:
(1)自主机器人与自动驾驶:凭借高精度的长尾类别分割能力与实时计算效率,SegDINO3D 可赋能服务机器人的室内导航与物体抓取,以及自动驾驶车辆的复杂路况感知,提升机器人与车辆对小目标、异形物体的识别精度。
(2)AR/VR 与数字孪生:在虚实融合场景中,该方法可快速完成真实环境的 3D 实例分割,为虚拟物体的精准放置与物理交互提供底层支撑;同时,在工业数字孪生构建中,能大幅降低 3D 模型标注成本,加速工厂、楼宇等场景的数字化建模。
(3)医疗影像分析:通过适配医学 3D 扫描数据(如 CT、MRI),SegDINO3D 可辅助医生精准分割肿瘤、器官等解剖结构,尤其在小病灶与不规则组织的识别上具备显著优势,为精准医疗提供技术支持。
(4)建筑与施工监测:利用 3D 扫描结合 SegDINO3D 的分割能力,可实现施工进度的自动化追踪与建筑缺陷检测,提升工程质量管控效率。
此外,它还为空间智能赋予了 “高精度、高性价比” 的三维环境理解能力,破解了以往空间建模数据依赖重、部署成本高的痛点;同时让具身智能在动态场景中具备更精准的障碍物识别、更灵活的目标交互能力,推动空间智能与具身智能从 “感知可用” 迈向 “决策可靠”。
实现方法
SegDINO3D 的整体框架如下图所示,核心在于 Encoder 和 Decoder 中对 2D 特征(SegDINO3D 研究团队选择了 DINO-X 与 Grounding DINO 等 2D 检测模型来提供 2D 特征)的合理利用,以及 3D 框调制交叉注意力(Box-Modulated Cross-Attention)机制。具体如下:
图 2 SegDINO3D 的整体框架
(1)Encoder 阶段:图像级特征增强(Image-Level)
传统的点云特征往往语义信息不足,SegDINO3D 研究团队提出通过最近视点采样(Nearest View Sampling)策略来利用 2D 图像的语义信息增强原始 3D 点云。
具体而言,对于每个 3D 点,并不盲目聚合所有视角的图片特征,而是只选取距离相机最近的 k 个视角图片,降低计算量的同时提取的特征也更加清晰可靠。之后再使用 3D Encoder 进行全局上下文融合,从而解决孤立视角之间缺乏 3D 空间一致性的问题。
(2)Decoder 阶段:物体级特征注入(Object-Level)
经过 3D Encoder 后,2D 特征的语义信息可能有所损失,因此 SegDINO3D 研究团队提出在 Decoder 阶段再次利用原始的强大 2D 语义特征。由于把成百上千张图片的特征图都存入显存以直接使用会引入巨大的计算开销,因此 SegDINO3D 框架选择直接利用 2D 检测模型输出的 2D queries,并将其视为物体级的高效压缩表示。
具体而言,SegDINO3D 先利用 2D 检测模型处理输入的图片并检测其中所有要求类别的物体,并设置阈值保留输出的高置信度的 queries。之后利用深度信息与相机参数将它们投影到 3D 空间,并通过 FPS 降采样保留 2048 个。
其后,3D query 直接通过距离感知交叉注意力(Distance-Aware Cross-Attention) 机制从投影到 3D 空间的 2D queries 中提取信息,该过程中会使用一个基于空间距离的注意力掩码,确保每个 3D query 只关注附近的 2D queries,减少计算量的同时实现了更准确的特征提取。
(3)3D 框调制交叉注意力(Box-Modulated Cross-Attention)机制
以往的 3D 实例分割模型通常使用掩码注意力(Mask-Attention)来与场景中的信息进行交互,但此时仅依赖于内容相似度而忽略了位置关系。最近有一些方法在此基础上引入了位置编码,但他们都是各向同性的(像一个球),无法捕捉到不同物体的尺度差异。
受到 2D 检测模型(DAB-DETR,DINO)的启发,SegDINO3D 研究团队将 3D query 建模为轴对齐的 3D 框(axis-aligned 3D boxes),并引入了辅助任务,要求每一个 3D query 估计物体的 3D 框。然后,我们使用估计的 3D 框来调制 positional attention map,使得 3D queries 能够根据物体的尺寸自适应地调制 attention 范围,从而更准确地从环境特征中提取信息。
实验指标和可视化
SegDINO3D 在 ScanNetv2 和 ScanNet200 等主流 benchmark 上都取得了 SOTA 表现,尤其是在更具挑战性,拥有更多长尾类别的 ScanNet200 benchmark 上实现了性能的巨大飞跃,相较于之前的方法,在 validation 和 hidden test sets 上分别提升了 +8.6mAP 和 +6.8mAP。
ScanNet200 Benchmark:
ScanNetv2 Validation Set:
Main Ablation:
ScanNet200 Hidden Test:
SegDINO3D 的可视化效果(Qualitative Performance):
(1)与以往方法的对比
(2)3D 框调制交叉注意力(Box-Modulated Cross-Attention)可视化
(3)可视化估计的 mask 与 bounding box





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

