


由深圳卫健委指导、IDEA 研究院 AI 平台技术研究中心(AIPT)与清华大学统计学研究中心俞声团队联合研发的生物医学信息本体系统(Biomedical Informatics Ontology System, BIOS)迎来重大更新,成为全球最大规模的开放生物医学知识图谱之一。
BIOS 2022V2 版数据集下载地址:https://bios.www.idea.edu.cn/Download
生物医学知识图谱是一种由生物医学概念、术语、关系以及 ID 系统等要素构成的数据库,是生物医学信息学的重要基础设施。30 余年来,美国的统一医学语言系统(Unified Medical Language System, UMLS)一直是生物医学知识图谱领域的标杆,其百万概念的巨大规模和开放属性,为生物医药行业英文领域的大数据分析、自然语言处理、人工智能开发和数据交换等作出了卓越贡献。
然而,随着大数据与人工智能时代来临,基于多数据库整合和专家整理的 UMLS 在数据规模、知识质量、开放程度及更新速度上,已无法满足快速增长的下游应用需求,国内更是长期缺乏高质量成体系的生物医学知识图谱。在上述背景下,IDEA 研究院联合清华大学完全自主研发了首个采用机器学习算法生成的大规模开放生物医学知识图谱 BIOS,其术语发现、语义分析、概念生成、关系发现、跨语言对齐完全由模型自动实现。
从 2021 年 11 月首次对外公布 BIOS 至今,研发团队根据真实数据效果,不断强化算法技术,终于取得了振奋人心的突破性进展。2022 年 7 月,BIOS 2022V2 版本(以下简称新版本)正式发布,实现术语和概念数量的千万级跃升,成为全球开放生物医学知识图谱领域新的领跑者。
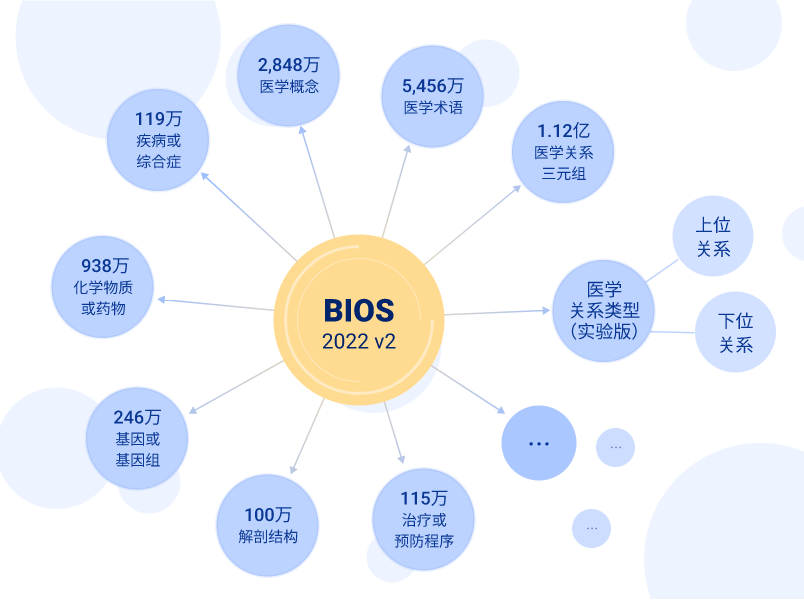
对比概念和术语仅有百万规模的上一版本,新版本共收录超 5400 万术语(3300 万英文、2100 万中文)以及超 2800 万医学概念,一举超越 UMLS 数倍以上。
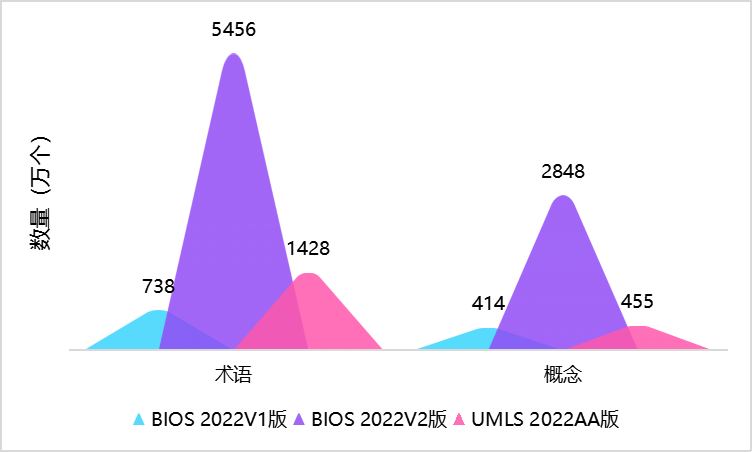
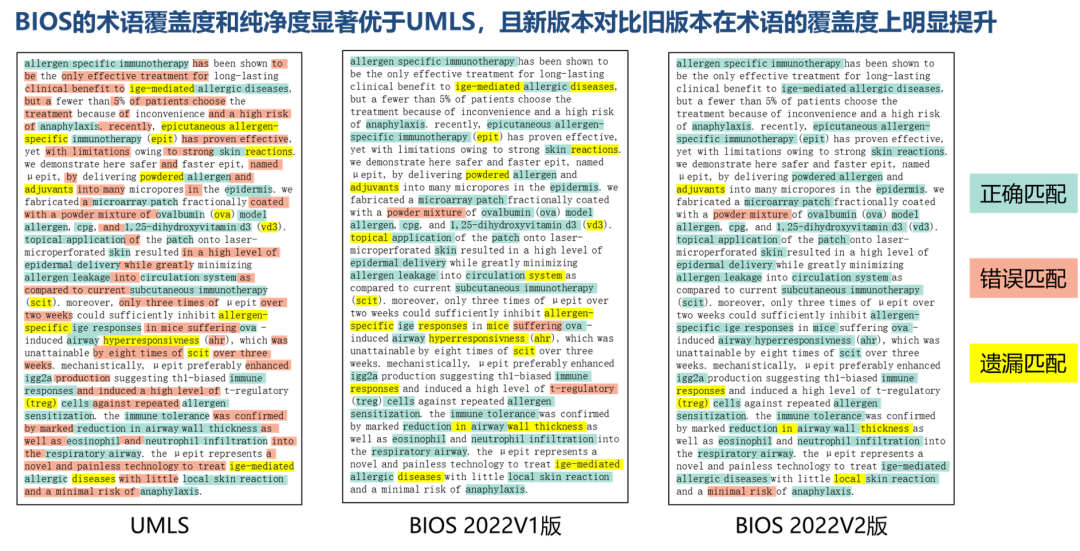
值得一提的是,纵然规模增长如此巨大,新版本的术语完整性和语义准确度不降反增,具体数据仍在严格评测中(预计将在下个版本公布),但可以先通过下图的一个实例,直观感受下对比效果。
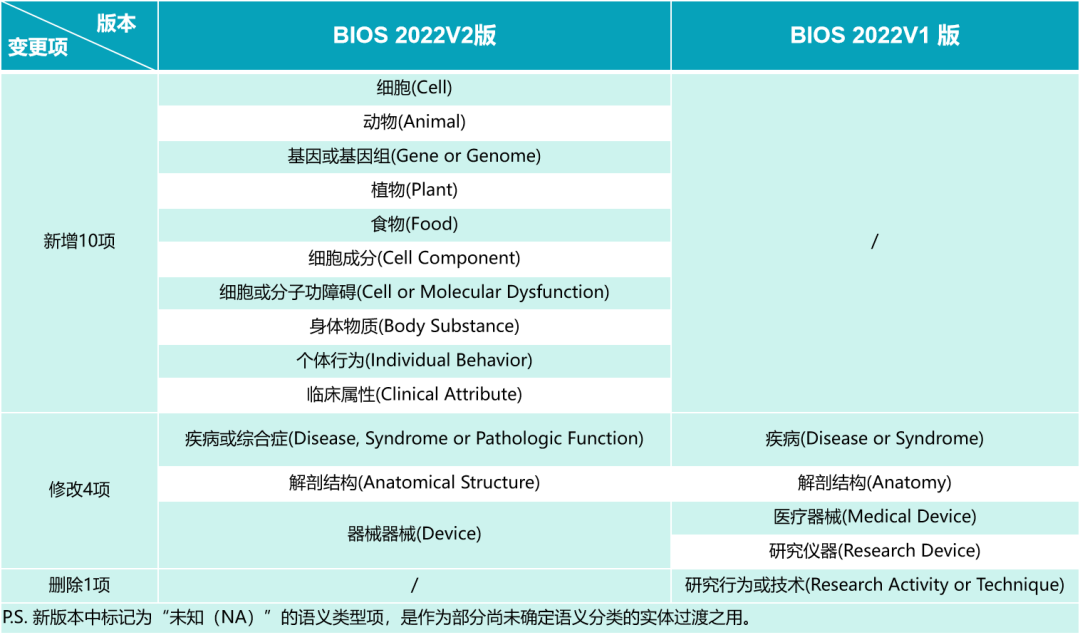
新版本在原有 18 种语义类型的基础上,又新增了基因、临床属性、身体物质等 10 项语义类型,并对部分语义类型做了修改和删除,极大地完善了语义类型体系,基本实现常见实体语义类型全覆盖。
对应数千万体量的实体概念,研发团队创新性地提出了由“基于文本的关系提取”到“基于大模型自有知识的关系生成”的模式,获得了超亿级别的关系三元组。本次版本先行发布其中 1.12 亿个上下位关系三元组,其他关系类别将在后续版本中逐步发布。
短短一年半的时间,BIOS 从无到有,再到初有所成,在规模体量上超越建设数十年的 UMLS。BIOS 充分证明了人工智能技术的巨大潜力,也打破了国内缺乏大规模开放生物医学知识图谱的空白局面,为国内医学大数据分析、AI 医疗技术发展提供了坚实基础支撑。
BIOS 的愿景是成为“值得信赖的全球开放医学知识全集”,未来,BIOS 将会在图谱规模和质量提升上持续发力。“坚持开放、广泛合作”也是 BIOS 始终坚持不变的精神,除了已按照 CC BY-NC-ND 4.0 授权协议开放数据集和构建技术外,团队还会陆续开放多种构建工具、示范应用等,并寻求和全球更多优秀伙伴建立合作,共同推进 BIOS 在 AI 医疗领域的应用。
由深圳卫健委指导、IDEA 研究院 AI 平台技术研究中心(AIPT)与清华大学统计学研究中心俞声团队联合研发的生物医学信息本体系统(Biomedical Informatics Ontology System, BIOS)迎来重大更新,成为全球最大规模的开放生物医学知识图谱之一。
BIOS 2022V2 版数据集下载地址:https://bios.www.idea.edu.cn/Download
生物医学知识图谱是一种由生物医学概念、术语、关系以及 ID 系统等要素构成的数据库,是生物医学信息学的重要基础设施。30 余年来,美国的统一医学语言系统(Unified Medical Language System, UMLS)一直是生物医学知识图谱领域的标杆,其百万概念的巨大规模和开放属性,为生物医药行业英文领域的大数据分析、自然语言处理、人工智能开发和数据交换等作出了卓越贡献。
然而,随着大数据与人工智能时代来临,基于多数据库整合和专家整理的 UMLS 在数据规模、知识质量、开放程度及更新速度上,已无法满足快速增长的下游应用需求,国内更是长期缺乏高质量成体系的生物医学知识图谱。在上述背景下,IDEA 研究院联合清华大学完全自主研发了首个采用机器学习算法生成的大规模开放生物医学知识图谱 BIOS,其术语发现、语义分析、概念生成、关系发现、跨语言对齐完全由模型自动实现。
从 2021 年 11 月首次对外公布 BIOS 至今,研发团队根据真实数据效果,不断强化算法技术,终于取得了振奋人心的突破性进展。2022 年 7 月,BIOS 2022V2 版本(以下简称新版本)正式发布,实现术语和概念数量的千万级跃升,成为全球开放生物医学知识图谱领域新的领跑者。
对比概念和术语仅有百万规模的上一版本,新版本共收录超 5400 万术语(3300 万英文、2100 万中文)以及超 2800 万医学概念,一举超越 UMLS 数倍以上。
值得一提的是,纵然规模增长如此巨大,新版本的术语完整性和语义准确度不降反增,具体数据仍在严格评测中(预计将在下个版本公布),但可以先通过下图的一个实例,直观感受下对比效果。
新版本在原有 18 种语义类型的基础上,又新增了基因、临床属性、身体物质等 10 项语义类型,并对部分语义类型做了修改和删除,极大地完善了语义类型体系,基本实现常见实体语义类型全覆盖。
对应数千万体量的实体概念,研发团队创新性地提出了由“基于文本的关系提取”到“基于大模型自有知识的关系生成”的模式,获得了超亿级别的关系三元组。本次版本先行发布其中 1.12 亿个上下位关系三元组,其他关系类别将在后续版本中逐步发布。
短短一年半的时间,BIOS 从无到有,再到初有所成,在规模体量上超越建设数十年的 UMLS。BIOS 充分证明了人工智能技术的巨大潜力,也打破了国内缺乏大规模开放生物医学知识图谱的空白局面,为国内医学大数据分析、AI 医疗技术发展提供了坚实基础支撑。
BIOS 的愿景是成为“值得信赖的全球开放医学知识全集”,未来,BIOS 将会在图谱规模和质量提升上持续发力。“坚持开放、广泛合作”也是 BIOS 始终坚持不变的精神,除了已按照 CC BY-NC-ND 4.0 授权协议开放数据集和构建技术外,团队还会陆续开放多种构建工具、示范应用等,并寻求和全球更多优秀伙伴建立合作,共同推进 BIOS 在 AI 医疗领域的应用。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

