


2022 IDEA 大会中,清华大学深圳国际研究生院 TBSI 首席教授、加拿大工程院院士张晓平,文远知行创始人兼首席执行官韩旭,碳硅智慧创始人兼首席执行官邓亚峰共同出现在 IDEA 研究院计算机视觉与机器人研究中心讲席科学家张磊主持的主题圆桌上,四人围绕“大数据 vs 小数据:得数据者得天下”进行了一场对话。

张磊以两篇文章的引用开启了本场圆桌讨论。第一是今年 6 月发表在《经济学人》杂志上的文章“Huge ‘foundation models’ are turbo-charging AI progress”(巨大的“基础模型”正在加速人工智能的进步)。第二是 4 月时 IEEE Spectrum 吴恩达专访中的观点“In AI,Small is the New Big”(人工智能,小即是大)。
1. Huge “foundation models” are turbo-charging AI progress. The Economist. June 11, 2022.
2. Andrew Ng: Unbiggen AI. IEEE Spectrum. April 2022.
https://spectrum.ieee.org/andrew-ng-data-centric-ai
自人工智能诞生到现在,随着社会算力提升,AI 模型参数量也不断增长。随着 GPT-3 问世,大模型被公认为是当前人工智能发展最行之有效的方向之一。过去三年中,大数据、大模型、大算力发展迅猛,接连出现了许多刷新科技界认知的成果。
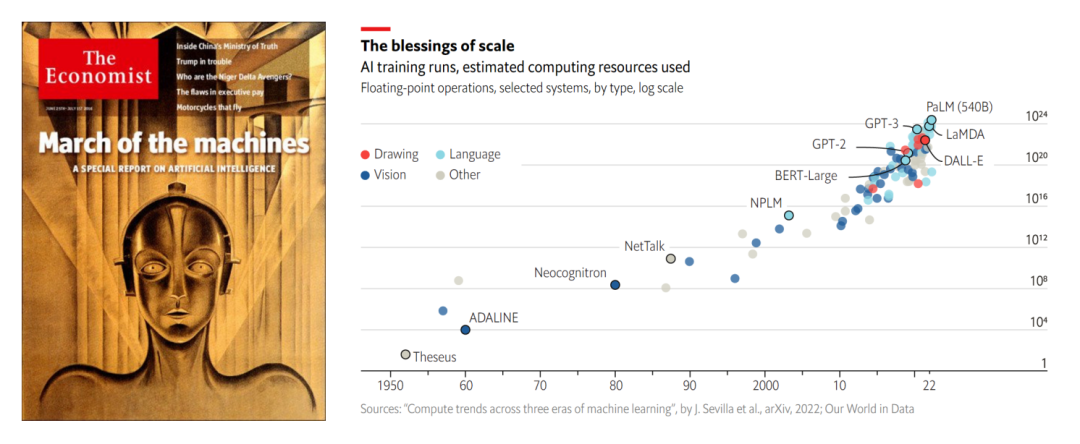
张磊指出,大数据带来的 AI 模型效果提升是有目共睹的,几乎可以说是数据驱动了第二代人工智能发展。但求大,是否依然是下一代人工智能的要寻求的突破方向?
邓亚峰认为,“大”必不可少,就像解一个方程式,需要有更多的条件数据去约束它。他例举,人的大脑里约有一千亿个神经元,智力的诞生必须建构在大量的数据、复杂的基础之上。当然除了数据大,还需要还得有高性能算法、优秀的模型结构和好的训练方法。
韩旭则举了一个业内津津乐道的例子。此前他所在的语音团队,受困于语料的严重不足,模型效果一直无法得到提升,同时在大洋彼岸,有一堆斯坦福的博士在调复杂模型,双方都想找到快速抬升模型表现的方法。此时团队中一个工程师想到了一个“天外飞仙”的招数,即通过 OCR 识别公司版权库中所有电视剧的字幕内容,一句一句把语料切出来,然后做语音。
“我跟他说这是一个非常 dirty 的数据,非常 dirty 的工作。他说‘没关系,我来清洗’,”韩旭回忆,“最后效果提升了好多,后来基于这份工作的一篇文章,被 MIT 评为 2017 年全球十大技术突破之一。”
邓亚峰感慨:“数据量和模型大小的增加确实能让效果发生比较本质的提升。”
张磊表示:“这个案例证明,在同等的目标效果下,当数据大到一定程度,不需要很复杂的算法。”
“目前的大数据往往是对系统显变量的静态和历史状态的被动观测,对动态系统来说常常缺失对隐变量的观测数据,从而难以预测动态系统的未来和因果关系。”张晓平认为,“数据赋能应该包括信息和数据处理全生命周期。”
信息和数据处理的全生命周期,被张晓平概括为四个字“感、通、算、决”,即传感、通信、计算、决策。他认为到目前为止,人工智能主要集中在计算环节,对具体问题主动感知、寻找合适变量和数据的理论和方法还缺乏研究,在其它环节中,主动数据赋能理论和应用也会有广阔的发展空间。

数据难收集,模型难训练。张磊引用了吴恩达在 IEEE Spectrum 专访中的观点佐证,工业领域里尤其是在视觉领域,有大量的长尾场景。其中的模型应用不像自然语言处理领域中那样具备那么高的通用性。每一个小问题,都需要定制化模型去解决。这些定制化模型,只能依靠该场景下的“小数据”。
韩旭从实际应用的角度分享了自己的观点:“我相信大力出奇迹。该干的苦功就要干,该做的基本功就要做。花点时间把好的数据清洗干净,真的非常重要。”张磊表示赞同,“这句是非常非常重要的分享,‘人工智能’这四个字里,看来‘人工’还是最重要。”
“无论大数据小数据,具有代表性的好数据才更有用。”张晓平认为,“代表性要求数据能够代表场景中数据真实的分布, 几十个有代表性的高信噪比小数据可能比 1 千个大数据或者 1 万个有偏见的低质量数据要更有效。” 而且在很多领域,比如有“双碳”要求的场景,终端产品很难有资源采集大量的数据,也没有相应的大算力,高信噪比小数据的获取就更为重要。所以我们更需要的是 smart data (巧数据)。
邓亚峰认为,仅有小数据可能并不能真正把落地的问题解决得很好,但如果能在模型设计包括利用其他领域的大数据去训练一些预训练的模型,可能是解决这个问题的路径。
张磊表示在这些场景中,只有小数据存在。如果遇到小数据太少的情况,问题解起来就比较难。“如何让大数据模型在实际应用中真正帮助小数据,需要研究上的创新。”
张磊:我们 IDEA 研究院计算机视觉与机器人研究中心也在数据、工具方面做尝试。包括我们自己的研究成果 DINO,希望做最好的目标检测器,相关工具包 detrex 也已经开源了。各位给我们研究中心的同学还有在座的、线上的观众做一些分享吧?
邓亚峰:现在我从计算机视觉转到生命科学,从人工智能的角度来说都是无缝迁移。在这么一个大一统的时代,不用给自己设限。
张晓平:我们聊的这些人工智能和数据赋能领域问题,是欢迎大家随时来挑战的,鼓励大家去做一些现在看起来还没有那么热门但也很重要的问题,没准你就是下一个图灵奖。
韩旭:多花点时间在数学上,如果能从理论上把深度学习好好解释一下,值五个图灵奖。
张磊:总结起来,在应用中,眼光要放在落地场景中去解决实际需求;而从学术角度,要做最基础的问题;在所有选择上,不要给自己设限。
2022 IDEA 大会中,清华大学深圳国际研究生院 TBSI 首席教授、加拿大工程院院士张晓平,文远知行创始人兼首席执行官韩旭,碳硅智慧创始人兼首席执行官邓亚峰共同出现在 IDEA 研究院计算机视觉与机器人研究中心讲席科学家张磊主持的主题圆桌上,四人围绕“大数据 vs 小数据:得数据者得天下”进行了一场对话。
张磊以两篇文章的引用开启了本场圆桌讨论。第一是今年 6 月发表在《经济学人》杂志上的文章“Huge ‘foundation models’ are turbo-charging AI progress”(巨大的“基础模型”正在加速人工智能的进步)。第二是 4 月时 IEEE Spectrum 吴恩达专访中的观点“In AI,Small is the New Big”(人工智能,小即是大)。
1. Huge “foundation models” are turbo-charging AI progress. The Economist. June 11, 2022.
2. Andrew Ng: Unbiggen AI. IEEE Spectrum. April 2022.
https://spectrum.ieee.org/andrew-ng-data-centric-ai
自人工智能诞生到现在,随着社会算力提升,AI 模型参数量也不断增长。随着 GPT-3 问世,大模型被公认为是当前人工智能发展最行之有效的方向之一。过去三年中,大数据、大模型、大算力发展迅猛,接连出现了许多刷新科技界认知的成果。
张磊指出,大数据带来的 AI 模型效果提升是有目共睹的,几乎可以说是数据驱动了第二代人工智能发展。但求大,是否依然是下一代人工智能的要寻求的突破方向?
邓亚峰认为,“大”必不可少,就像解一个方程式,需要有更多的条件数据去约束它。他例举,人的大脑里约有一千亿个神经元,智力的诞生必须建构在大量的数据、复杂的基础之上。当然除了数据大,还需要还得有高性能算法、优秀的模型结构和好的训练方法。
韩旭则举了一个业内津津乐道的例子。此前他所在的语音团队,受困于语料的严重不足,模型效果一直无法得到提升,同时在大洋彼岸,有一堆斯坦福的博士在调复杂模型,双方都想找到快速抬升模型表现的方法。此时团队中一个工程师想到了一个“天外飞仙”的招数,即通过 OCR 识别公司版权库中所有电视剧的字幕内容,一句一句把语料切出来,然后做语音。
“我跟他说这是一个非常 dirty 的数据,非常 dirty 的工作。他说‘没关系,我来清洗’,”韩旭回忆,“最后效果提升了好多,后来基于这份工作的一篇文章,被 MIT 评为 2017 年全球十大技术突破之一。”
邓亚峰感慨:“数据量和模型大小的增加确实能让效果发生比较本质的提升。”
张磊表示:“这个案例证明,在同等的目标效果下,当数据大到一定程度,不需要很复杂的算法。”
“目前的大数据往往是对系统显变量的静态和历史状态的被动观测,对动态系统来说常常缺失对隐变量的观测数据,从而难以预测动态系统的未来和因果关系。”张晓平认为,“数据赋能应该包括信息和数据处理全生命周期。”
信息和数据处理的全生命周期,被张晓平概括为四个字“感、通、算、决”,即传感、通信、计算、决策。他认为到目前为止,人工智能主要集中在计算环节,对具体问题主动感知、寻找合适变量和数据的理论和方法还缺乏研究,在其它环节中,主动数据赋能理论和应用也会有广阔的发展空间。
数据难收集,模型难训练。张磊引用了吴恩达在 IEEE Spectrum 专访中的观点佐证,工业领域里尤其是在视觉领域,有大量的长尾场景。其中的模型应用不像自然语言处理领域中那样具备那么高的通用性。每一个小问题,都需要定制化模型去解决。这些定制化模型,只能依靠该场景下的“小数据”。
韩旭从实际应用的角度分享了自己的观点:“我相信大力出奇迹。该干的苦功就要干,该做的基本功就要做。花点时间把好的数据清洗干净,真的非常重要。”张磊表示赞同,“这句是非常非常重要的分享,‘人工智能’这四个字里,看来‘人工’还是最重要。”
“无论大数据小数据,具有代表性的好数据才更有用。”张晓平认为,“代表性要求数据能够代表场景中数据真实的分布, 几十个有代表性的高信噪比小数据可能比 1 千个大数据或者 1 万个有偏见的低质量数据要更有效。” 而且在很多领域,比如有“双碳”要求的场景,终端产品很难有资源采集大量的数据,也没有相应的大算力,高信噪比小数据的获取就更为重要。所以我们更需要的是 smart data (巧数据)。
邓亚峰认为,仅有小数据可能并不能真正把落地的问题解决得很好,但如果能在模型设计包括利用其他领域的大数据去训练一些预训练的模型,可能是解决这个问题的路径。
张磊表示在这些场景中,只有小数据存在。如果遇到小数据太少的情况,问题解起来就比较难。“如何让大数据模型在实际应用中真正帮助小数据,需要研究上的创新。”
张磊:我们 IDEA 研究院计算机视觉与机器人研究中心也在数据、工具方面做尝试。包括我们自己的研究成果 DINO,希望做最好的目标检测器,相关工具包 detrex 也已经开源了。各位给我们研究中心的同学还有在座的、线上的观众做一些分享吧?
邓亚峰:现在我从计算机视觉转到生命科学,从人工智能的角度来说都是无缝迁移。在这么一个大一统的时代,不用给自己设限。
张晓平:我们聊的这些人工智能和数据赋能领域问题,是欢迎大家随时来挑战的,鼓励大家去做一些现在看起来还没有那么热门但也很重要的问题,没准你就是下一个图灵奖。
韩旭:多花点时间在数学上,如果能从理论上把深度学习好好解释一下,值五个图灵奖。
张磊:总结起来,在应用中,眼光要放在落地场景中去解决实际需求;而从学术角度,要做最基础的问题;在所有选择上,不要给自己设限。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

