


一年一度的 CVPR 2024 论文录用结果出炉,粤港澳大湾区数字经济研究院(简称“IDEA 研究院”)有四篇论文入选。
CVPR 是计算机视觉领域最具权威性和影响力的学术会议之一,全称 Conference on Computer Vision and Pattern Recognition(“国际计算机视觉与模式识别大会”)。据 CVPR 官方统计,今年共提交了 11,532 份有效论文,创历史新高。录用率为 23.6%,比去年降低 2.2%。
IDEA 研究院入选论文分别针对视频编辑、3D 虚拟人生成、现实世界 HOI 检测以及通用视觉情境提示框架进行研究。本期 Paper Sparks 为大家详细介绍论文中的技术亮点。
CVPR 论文主题一览
· STEM inversion:无缝替换现有 DDIM 反演步骤并提升其视频编辑能力
· DiffSHEG:实时响应音频输入,高效生成连贯、富有表现力且表情和手势同步的虚拟人
· MP-HOI:解决文本描述中的泛化难题,实现开放世界中的 HOI 检测
· DINOv:支持通用分割和参考分割,可根据视觉提示关联多个或单个对象
01

本文提出了一个时空期望最大化 (Spatial-Temporal Expectation-Maximization, STEM) 的零样本视频编辑反演方法,可以无缝替换现有的 diffusion-based 视频编辑方法中的 DDIM 反演步骤,并提升它们的视频编辑能力。
对比传统的二维 DDIM inversion 或时空数据 DDIM inversion,STEM 反演方法以期望最大化的方式构建密集的视频特征,并迭代估计一个更紧凑的基础集来表示整个视频。每一帧都应用了固定和全局的表示进行反演,有助于在重建和编辑过程中保持时间一致性。

使用 STEM 反演方法将视频中的主体(左)替换成神奇女侠(右)。
实验结果表明,STEM 反演方法可以更好地解决视频编辑中的闪烁问题、3D 对应关系建模难题、时空一致性问题以及计算复杂性问题,具有广泛的应用前景。
本项工作由香港大学、IDEA 研究院、北京大学和清华大学共同完成。
02

在实时生成与语音同步的人体形象时,人体的姿态与表情通常是独立生成的,这可能导致生成的人体形象在动作与表情上缺乏自然的同步性和协调性。本文提出了一种基于扩散模型的方法 DiffSHEG (Diffusion-based approach for Speech-driven Holistic 3D Expression and Gesture),用于语音驱动的整体 3D 表达和任意长度的姿态生成。
DiffSHEG 框架实现了从表情到手势的单向信息流,能更好地捕捉表情和手势之间的联合分布而不会互相干扰,从而进行合理匹配。此外,该方法引入了一种基于外部重绘的采样策略(Fast Out-Painting-based Partial Autoregressive Sampling, FOPPAS),用于扩散模型中的任意长序列生成,提供了灵活性和计算的高效性。
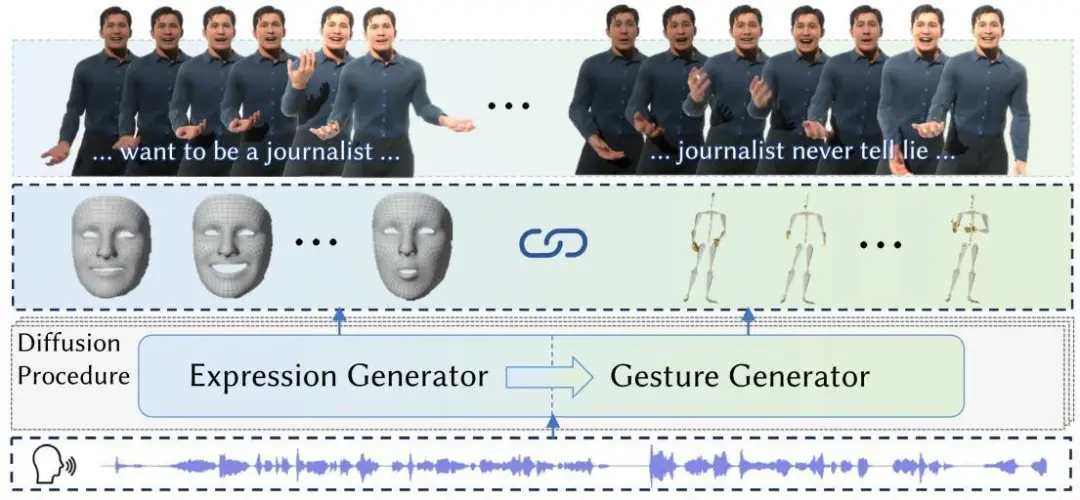
DiffSHEG 功能示例:以语音生成人体肢体动作和面部表情,以输入的声音驱动自己的虚拟化身。
通过评估和用户反馈,DiffSHEG 方法能够实时响应音频输入,高效地生成动作连贯且富有表现力、同时表情和手势同步的虚拟人,推动数字人和具身智能的发展。
本项工作由 IDEA 研究院和香港科技大学(广州)共同完成。
03

人体-物体交互检测(Human-Object Interaction, HOI)对于理解人类行为、进行场景分析和提高机器对视觉信息的理解能力至关重要,然而现有的方法难以处理带有高歧义性的文本描述。
为了实现开放世界中的 HOI 检测,本文提出了一种强大的多模态 HOI 检测器 MP-HOI(Multi-modal Prompt-based HOI)。它将视觉提示集成到现有的仅由语言引导的 HOI 检测器中,以处理文本描述在泛化中面临的困难,并解决交互复杂性高的场景。
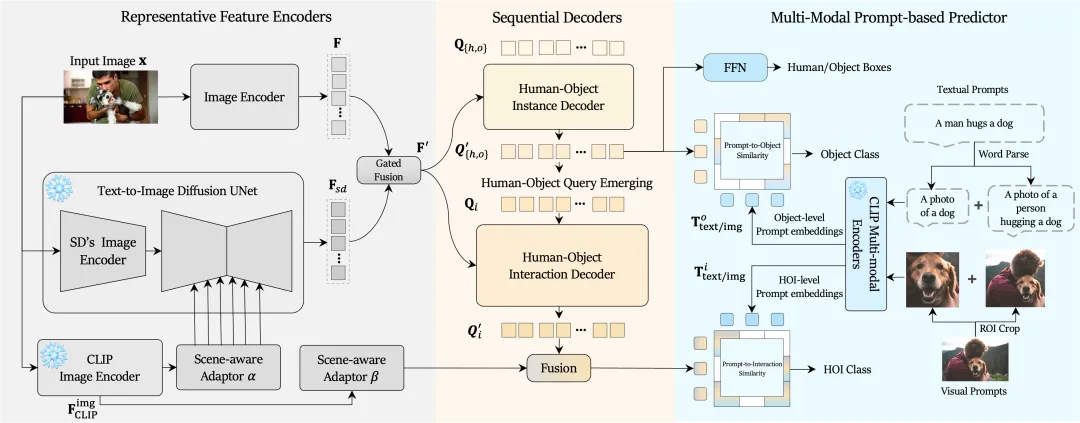
MP-HOI 的框架由三个部分构成。
为了促进 MP-HOI 的训练,作者构建了一个大规模的 HOI 数据集 Magic-HOI,将六个现有数据集合并到一个统一的标签空间中。为了解决 Magic-HOI 数据集中的长尾问题,作者引入了一个自动化的管道,用于生成真实标注的 HOI 图像,并提出了一个高质量的合成 HOI 数据集 SynHOI,包含 10 万张图像。利用这两个数据集,MP-HOI 将 HOI 任务优化为多模态提示与物体及交互之间的相似性学习过程,通过统一对比损失(unified contrastive loss)来学习大规模数据中可泛化和可转移的物体及交互表示。
MP-HOI 可以作为一个通用的 HOI 检测器,其 HOI 词汇量已超过现有专家模型 30 倍以上。同时,实验结果表明,MP-HOI 在现实世界场景中展示了卓越的零样本能力,并在多个基准测试中持续刷新 SOTA。
本项工作由香港中文大学(深圳)和 IDEA 研究院共同完成。
04

在大型语言模型中,上下文提示(in-context prompting)已成为提升零样本能力的一种普遍方法,但这一理念在视觉领域中尚未得到充分探索。现有的视觉提示方法未能解决通用的视觉任务,如开集分割和目标检测。
为了解决以上两种难点,本文提出了一个通用视觉情境提示框架 DINOv。作者基于编码器-解码器架构,开发了一个多功能的提示编码器,以支持多种提示,如笔画、框和点。通过进一步增强,使其可以将任意数量的参考图像片段作为上下文。这种统一简化了模型设计,并使 DINOv 能够、使用语义标注数据和未标注数据,从而获得更好的性能。

DINOv 支持通用分割和参考分割,可以根据用户输入的视觉提示关联多个或单个对象。用户可以输入一个或多个情境视觉提示(如点、框等)以提高分割性能。
广泛的实验表明,DINOv 在闭集数据集中有出色的参考和通用分割能力,并在许多开集数据集上也有良好的效果。通过在 COCO 和 SA-1B 上的联合训练,DINOv 在 COCO 和 ADE20K 上分别达到了 57.7 PQ 和 23.2 PQ,展现了其在自动驾驶、医疗影像分析和智能监控等领域的应用潜力。
本项工作由香港科技大学、华南理工大学、IDEA 研究院、清华大学、威斯康星大学麦迪逊分校和微软研究院共同完成。
一年一度的 CVPR 2024 论文录用结果出炉,粤港澳大湾区数字经济研究院(简称“IDEA 研究院”)有四篇论文入选。
CVPR 是计算机视觉领域最具权威性和影响力的学术会议之一,全称 Conference on Computer Vision and Pattern Recognition(“国际计算机视觉与模式识别大会”)。据 CVPR 官方统计,今年共提交了 11,532 份有效论文,创历史新高。录用率为 23.6%,比去年降低 2.2%。
IDEA 研究院入选论文分别针对视频编辑、3D 虚拟人生成、现实世界 HOI 检测以及通用视觉情境提示框架进行研究。本期 Paper Sparks 为大家详细介绍论文中的技术亮点。
CVPR 论文主题一览
· STEM inversion:无缝替换现有 DDIM 反演步骤并提升其视频编辑能力
· DiffSHEG:实时响应音频输入,高效生成连贯、富有表现力且表情和手势同步的虚拟人
· MP-HOI:解决文本描述中的泛化难题,实现开放世界中的 HOI 检测
· DINOv:支持通用分割和参考分割,可根据视觉提示关联多个或单个对象
01
本文提出了一个时空期望最大化 (Spatial-Temporal Expectation-Maximization, STEM) 的零样本视频编辑反演方法,可以无缝替换现有的 diffusion-based 视频编辑方法中的 DDIM 反演步骤,并提升它们的视频编辑能力。
对比传统的二维 DDIM inversion 或时空数据 DDIM inversion,STEM 反演方法以期望最大化的方式构建密集的视频特征,并迭代估计一个更紧凑的基础集来表示整个视频。每一帧都应用了固定和全局的表示进行反演,有助于在重建和编辑过程中保持时间一致性。
使用 STEM 反演方法将视频中的主体(左)替换成神奇女侠(右)。
实验结果表明,STEM 反演方法可以更好地解决视频编辑中的闪烁问题、3D 对应关系建模难题、时空一致性问题以及计算复杂性问题,具有广泛的应用前景。
本项工作由香港大学、IDEA 研究院、北京大学和清华大学共同完成。
02
在实时生成与语音同步的人体形象时,人体的姿态与表情通常是独立生成的,这可能导致生成的人体形象在动作与表情上缺乏自然的同步性和协调性。本文提出了一种基于扩散模型的方法 DiffSHEG (Diffusion-based approach for Speech-driven Holistic 3D Expression and Gesture),用于语音驱动的整体 3D 表达和任意长度的姿态生成。
DiffSHEG 框架实现了从表情到手势的单向信息流,能更好地捕捉表情和手势之间的联合分布而不会互相干扰,从而进行合理匹配。此外,该方法引入了一种基于外部重绘的采样策略(Fast Out-Painting-based Partial Autoregressive Sampling, FOPPAS),用于扩散模型中的任意长序列生成,提供了灵活性和计算的高效性。
DiffSHEG 功能示例:以语音生成人体肢体动作和面部表情,以输入的声音驱动自己的虚拟化身。
通过评估和用户反馈,DiffSHEG 方法能够实时响应音频输入,高效地生成动作连贯且富有表现力、同时表情和手势同步的虚拟人,推动数字人和具身智能的发展。
本项工作由 IDEA 研究院和香港科技大学(广州)共同完成。
03
人体-物体交互检测(Human-Object Interaction, HOI)对于理解人类行为、进行场景分析和提高机器对视觉信息的理解能力至关重要,然而现有的方法难以处理带有高歧义性的文本描述。
为了实现开放世界中的 HOI 检测,本文提出了一种强大的多模态 HOI 检测器 MP-HOI(Multi-modal Prompt-based HOI)。它将视觉提示集成到现有的仅由语言引导的 HOI 检测器中,以处理文本描述在泛化中面临的困难,并解决交互复杂性高的场景。
MP-HOI 的框架由三个部分构成。
为了促进 MP-HOI 的训练,作者构建了一个大规模的 HOI 数据集 Magic-HOI,将六个现有数据集合并到一个统一的标签空间中。为了解决 Magic-HOI 数据集中的长尾问题,作者引入了一个自动化的管道,用于生成真实标注的 HOI 图像,并提出了一个高质量的合成 HOI 数据集 SynHOI,包含 10 万张图像。利用这两个数据集,MP-HOI 将 HOI 任务优化为多模态提示与物体及交互之间的相似性学习过程,通过统一对比损失(unified contrastive loss)来学习大规模数据中可泛化和可转移的物体及交互表示。
MP-HOI 可以作为一个通用的 HOI 检测器,其 HOI 词汇量已超过现有专家模型 30 倍以上。同时,实验结果表明,MP-HOI 在现实世界场景中展示了卓越的零样本能力,并在多个基准测试中持续刷新 SOTA。
本项工作由香港中文大学(深圳)和 IDEA 研究院共同完成。
04
在大型语言模型中,上下文提示(in-context prompting)已成为提升零样本能力的一种普遍方法,但这一理念在视觉领域中尚未得到充分探索。现有的视觉提示方法未能解决通用的视觉任务,如开集分割和目标检测。
为了解决以上两种难点,本文提出了一个通用视觉情境提示框架 DINOv。作者基于编码器-解码器架构,开发了一个多功能的提示编码器,以支持多种提示,如笔画、框和点。通过进一步增强,使其可以将任意数量的参考图像片段作为上下文。这种统一简化了模型设计,并使 DINOv 能够、使用语义标注数据和未标注数据,从而获得更好的性能。
DINOv 支持通用分割和参考分割,可以根据用户输入的视觉提示关联多个或单个对象。用户可以输入一个或多个情境视觉提示(如点、框等)以提高分割性能。
广泛的实验表明,DINOv 在闭集数据集中有出色的参考和通用分割能力,并在许多开集数据集上也有良好的效果。通过在 COCO 和 SA-1B 上的联合训练,DINOv 在 COCO 和 ADE20K 上分别达到了 57.7 PQ 和 23.2 PQ,展现了其在自动驾驶、医疗影像分析和智能监控等领域的应用潜力。
本项工作由香港科技大学、华南理工大学、IDEA 研究院、清华大学、威斯康星大学麦迪逊分校和微软研究院共同完成。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

