


2025 年国际计算机视觉与模式识别会议(Conference on Computer Vision and Pattern Recognition,CVPR 2025)于 6 月 11 至 15 日在美国田纳西州纳什维尔召开。CVPR 是计算机视觉乃至人工智能领域最具学术影响力的顶级会议之一。
公开资料显示,今年大会共收到 13,008 份论文,相比去年增长了 13%。最终有 2,872 篇论文被接收,整体接收率约为 22.1%,创近年新低。
IDEA 研究院有 5 篇论文入选 CVPR 2025,其中一篇获得 Highlight(占被接收论文的 13.7%),一篇获得 Workshop@CVPR25 的分享邀请。
本期 Paper Sparks 为大家详细介绍 IDEA 研究院入选 CVPR 2025 的亮点研究。
CVPR 论文主题一览
· SkillMimic:入选 Highlight。实现无需人工设计奖励的多样化交互场景与复杂长时程任务组合,兼具泛化性与可扩展性。
· HRAvatar:从单目视频重建高质量、可重光照的 3D 人头头像。
· HumanMM:解决多镜头切换视频中的世界坐标系 3D 人体运动重建问题。
· LeanGaussian:从单个 RGB 图像合成新视图的过程中直接建模 3D 高斯,打破像素或点云对应约束。
· HandOS:通过单一的处理阶段直接重建人手姿态,提高重建的准确性与效率。
01

传统强化学习方法在人-物交互(HOI)任务中依赖人工设计的技能特定奖励(Skill-specific Rewards),这类方法不仅耗时,且难以泛化到多样化的交互场景。尤其在篮球这类动态、多智能体、需精确协作的场景中,现有方法无法通过单一策略学习多种技能,也无法完成复杂的长时程任务。本文提出了一种 SkillMimic 的模仿学习框架,实现统一、可扩展的交互技能学习。
区别于传统方法,SkillMimic 的实现原理是基于数据驱动的模仿学习框架。该框架通过强化学习训练一个交互技能策略(Interaction Skill Policy),同时设计了统一的 HOI 模仿奖励函数,以模仿多样化的 HOI 状态转移。再训练一个高层控制器(High-Level Controller),复用学习到的交互技能来完成复杂任务。这使得 SkillMimic 无需为每个技能设计单独的奖励函数便能掌握多种交互技能,还能促进技能转换,降低工程成本的同时提高了学习效率。为解决传统方法中因接触建模不足导致的非自然运动问题,框架通过接触图奖励(Contact Graph Rewards)提高了交互的精确性和自然性。
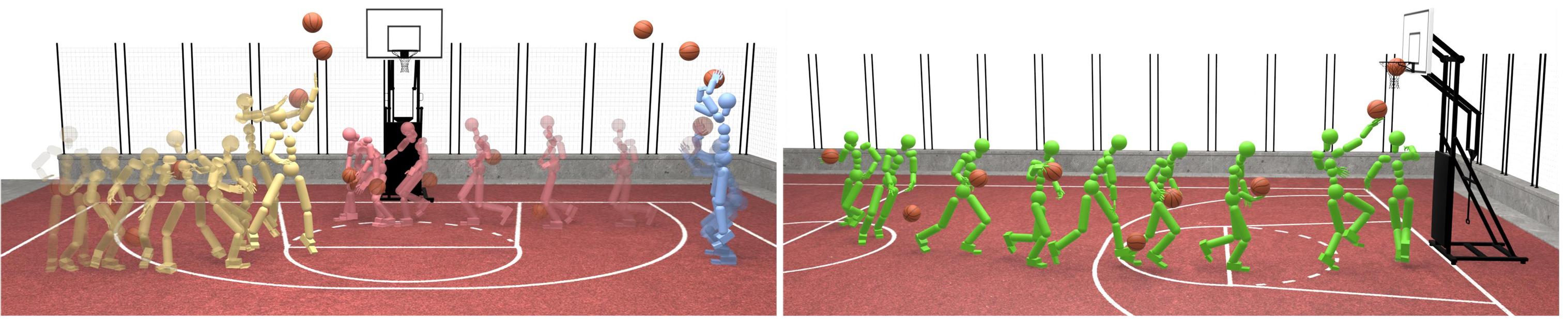
SkillMimic 的效果示意图,能够学习包括投篮(蓝色)、运球(红色)、上篮和投篮(黄色)的基础动作以及会连续得分的复杂的动作(绿色)。
通过在两个不同的数据集 BallPlay-V 和 BallPlay-V 上进行测试,SkillMimic 在典型篮球技能(捡球、运球、上篮、投篮)的成功率均优于两种经典模仿学习方法 DeepMimic 和 AMP:SkillMimic 在需精确接触的任务(如捡球)中表现最优,成功率(86.7%)比 DeepMimic 高 4.4 倍,而 AMP 则为 0%。在高级篮球任务((投篮、带球、绕圈、得分)的对比中,SkillMimic 是唯一能完成复杂任务的方法,而传统方法 PPO、ASE 成功率均为 0%。同时随着数据规模的增长,SkillMimic 的多样性和泛化能力也会提高,并且技能切换和鲁棒性更强。
本研究为可扩展及可泛化的交互技能学习开辟了新方向,有望为机器人在不同领域,如家庭任务、其他体育项目等的实际应用提供思路。
本项工作获得今年的 Highlight,由香港科技大学、宇树科技、北京大学深圳研究生院、清华大学、IDEA 研究院、腾讯和卡内基梅隆大学共同完成。
02

从单目视频中重建高质量、可重光照的 3D 人头头像,是一项极具价值的任务。然而,由于单目输入的信息有限,加上头部姿态和面部运动的复杂性,使得任务变得极具挑战性。本文提出了 HRAvatar,这是一种基于 3D Gaussian Splatting 的方法,来弥补传统方法面临的问题。
HRAvatar 采用了可学习的形变表示和混合蒙皮策略,为每个高斯点独立学习形状和运动参数,使其能灵活适应不同人的独特面部变形,让重建的头像更加逼真和精细。再利用端到端表情编码器,通过训练直接优化表情参数,减少传统方法中基于伪标签(如 2D 关键点)的跟踪误差。为了支持实时重光照与材质编辑(分解反照率、粗糙度),HRAvatar 使用了基于物理的着色方式,增强了视觉效果的真实性和沉浸感。

通过输入单目视频,HRAvatar 能够重建出高质量且可动画的 3D 头像,并支持真实感重光照效果以及简单的材质编辑。
对比传统方法,HRAvatar 在 INSTA、HDTF 和自采集数据集上的实验证明了其在 PSNR、MAE、SSIM 和 LPIPS 等指标上具有显著优势。并且在自驱动、跨驱动和重光照任务中,HRAvatar 还原了更精细的纹理(如牙齿、毛发)和几何细节(如耳部)。
HRAvatar 可广泛应用于虚拟人、数字替身等高保真数字角色构建,适用于影视、游戏与元宇宙场景。它支持真实表情和光照还原,适合用于沉浸式 VR/AR 体验、个性化社交和远程通信。该技术还能赋能 AI 内容创作、自动动画生成等领域,降低成本同时提升交互真实感与表现力。
本项工作被 Photo-realistic 3D Head Avatars Workshop@CVPR25 邀请进行报告,由 IDEA 研究院和清华大学共同完成。
03

长时间序列的人体运动对于运动生成和理解等应用极具价值,但恢复这些运动极具挑战性。现有方法主要集中在单镜头视频上,或仅简化多镜头在相机空间中的对齐。本文提出了名为 HumanMM 的新框架,解决从包含多个镜头切换的野外视频中恢复世界坐标系下的 3D 人体运动的问题。
HumanMM 框架采用了镜头切换检测器识别视频中的镜头切换帧,确保了人体姿态和方向在世界坐标系下的准确性和时间一致性。同时使用双向 LSTM 基轨迹预测器和轨迹优化器,平滑人体姿态并缓解脚滑问题,使得运动的自然性得到提升。对比传统方法,HumanMM 通过增强的摄像机轨迹估计(Masked LEAP-VO)和人体运动对齐模块,提高了在多镜头视频中恢复人体运动的鲁棒性。

HumanMM 框架概览。顶部:我们以两个包含镜头切换的多镜头乒乓球比赛视频作为输入,目标是从两个视频中分别恢复两名运动员(马龙和樊振东)的动作。第一个视频由三个镜头(“①”、“②” 和 “③”)组成,第二个视频由两个镜头(“④” 和 “⑤”)恢复而成。底部:我们恢复了两名运动员的动作(马龙为绿色,樊振东为粉色),以及每个视频不同镜头和相机姿态下的运动。恢复的运动与视频中的运动对齐。
论文自建了一个基于现有的公共 3D 人体数据集 ms-Motion,将 HumanMM 和现有方法在 ROE(方向误差)、RTE(平移误差)、Jitter(抖动)、Foot Sliding(脚部滑动)等指标上进行对比。实验结果表明,HumanMM 的 PA-MPJPE(36.88 vs 基线 72.34)、RTE(2.56m vs 基线 9.62m)等指标显著优于现有方法 SLAHMR、WHAM 和 GVHMR。
该研究能推动 3D 人体运动恢复技术发展,还能提升计算机对复杂运动场景的理解,为体育、影视、游戏等多领域提供支持。
本项工作由清华大学、IDEA 研究院、约翰霍普金斯大学、芝加哥大学、香港科技大学和香港大学共同完成。
04

从单个 RGB 图像合成新视图的现有方法通常通过像素或点云对应关系来回归高斯分布,这会导致资源浪费且缺乏准确的几何和纹理。本文介绍了一种名为 LeanGaussian 的新方法,通过可变形 Transformer直接建模 3D 高斯,打破像素或点云对应约束。
LeanGaussian 的核心是将每个查询视为一个 3D 高斯椭球体,通过多层解码器迭代优化其参数,避免了因像素或点云对应关系导致的高斯分布过度使用。并且可以根据任务的需求任意调整模型复杂度,不仅提高了资源利用效率,也能在短时间内完成高质量的三维重建和渲染任务。同时,LeanGaussian 将每个高斯的 3D 中心投影到 2D 图像平面,作为可变形注意力机制的参考点,自动关联最相关的图像特征。这能够更准确地捕捉三维物体的几何形状和纹理信息,避免了过度拟合其他表示的问题。
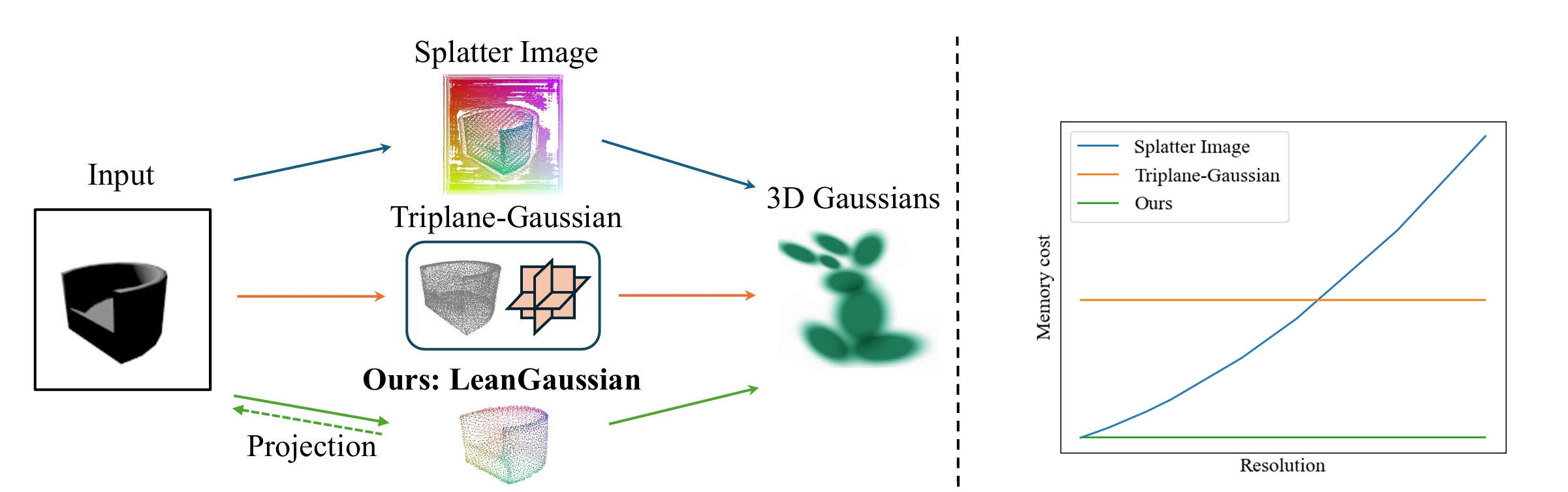
(a) LeanGaussian 和现有方法的对比
(b) LeanGaussian 和现有方法在显存使用情况的对比
通过在 ShapeNet SRN 数据集和 Google Scanned Objects 数据集上进行验证,LeanGaussian 在两个数据集上分别以 25.44 和 22.36 的 PSNR 优于现有方法约 6.1%。此外,该方法在三维重建速度和渲染速度上也表现出色,分别达到 7.2 FPS 和 500 FPS。实验还表明,该方法在远离输入视图的视图上也具有良好的性能,相较于现有方法,其性能下降幅度较小。
未来,LeanGaussian 可以进一步优化以生成更复杂的场景和更精细的几何细节。同时,其在处理自遮挡和背景纹理生成方面的改进也为未来研究提供了方向。
本项工作由 IDEA 研究院、香港科技大学和香港中文大学(深圳)共同完成。
05

传统手部重建方法依赖多阶段流程,包括检测、左右手识别和姿态估计,存在冗余计算和累积误差问题。本文提出了一个用于 3D 手部重建的端到端框架 HandOS,创新性地将手部检测、2D 姿态估计和 3D 网格重建整合到一个单一的处理阶段中,从而避免了传统多阶段方法中的不足。
具体来说,HandOS 使用了冻结检测器作为基础来定位手部区域,通过“侧调谐”(Side Tuning)生成补充特征,保留检测能力的同时增强姿态语义。再通过交互式 2D-3D 解码器来同时学习 2D 和 3D 特征,这使得 HandOS 能够更准确地捕捉手部的几何结构和空间关系,简化了工作流程的同时减少了由于多阶段处理导致的误差累积,最终提高了重建的准确性。
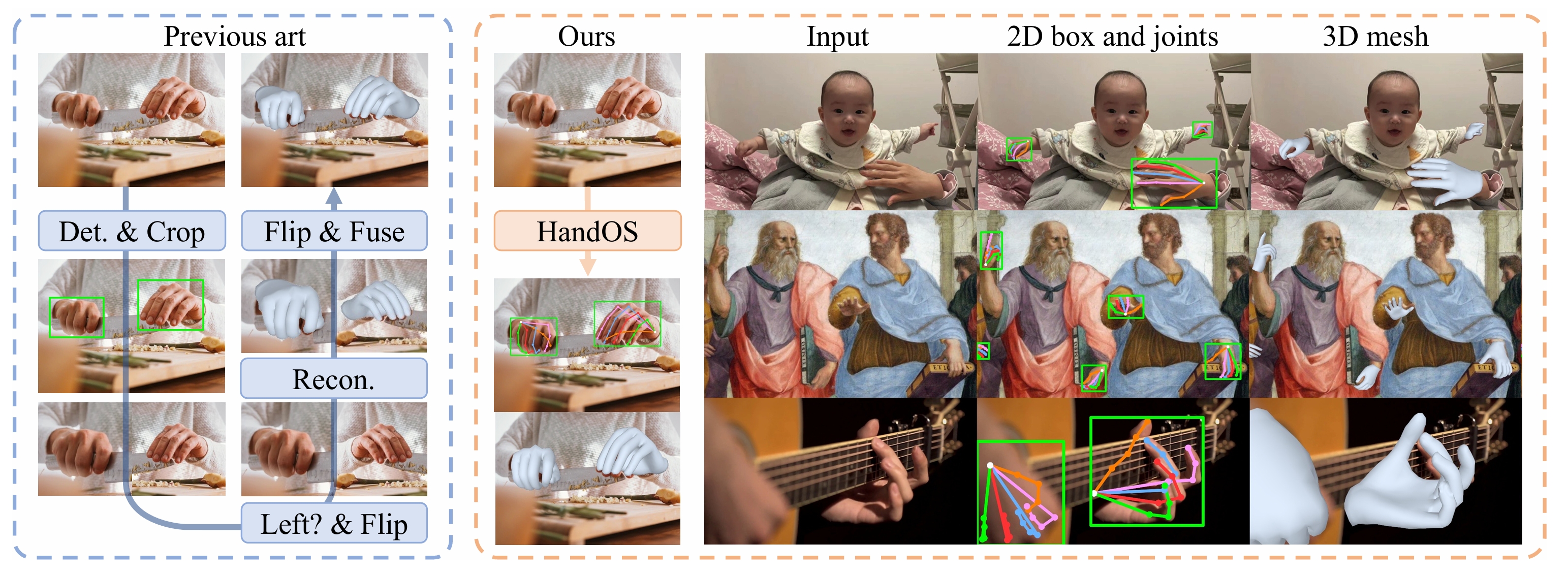
HandOS,一种单阶段手部重建方法,显著简化了传统流程。此外,实验表明 HandOS 能有效适应多样化复杂场景(如遮挡、密集物体等),凸显其在实际应用中的高适用性。
HandOS 在多个公共基准测试中的评估验证了它在精度、鲁棒性、效率和泛化能力等多项指标上优于传统技术。
该方法可以运用于现实技术、行为理解、交互建模和具身智能等领域,对人体行为理解和机器人动作学习具有重要意义。
本项工作由北京大学工学院先进制造与机器人系、IDEA 研究院和中国科学院大学共同完成。
2025 年国际计算机视觉与模式识别会议(Conference on Computer Vision and Pattern Recognition,CVPR 2025)于 6 月 11 至 15 日在美国田纳西州纳什维尔召开。CVPR 是计算机视觉乃至人工智能领域最具学术影响力的顶级会议之一。
公开资料显示,今年大会共收到 13,008 份论文,相比去年增长了 13%。最终有 2,872 篇论文被接收,整体接收率约为 22.1%,创近年新低。
IDEA 研究院有 5 篇论文入选 CVPR 2025,其中一篇获得 Highlight(占被接收论文的 13.7%),一篇获得 Workshop@CVPR25 的分享邀请。
本期 Paper Sparks 为大家详细介绍 IDEA 研究院入选 CVPR 2025 的亮点研究。
CVPR 论文主题一览
· SkillMimic:入选 Highlight。实现无需人工设计奖励的多样化交互场景与复杂长时程任务组合,兼具泛化性与可扩展性。
· HRAvatar:从单目视频重建高质量、可重光照的 3D 人头头像。
· HumanMM:解决多镜头切换视频中的世界坐标系 3D 人体运动重建问题。
· LeanGaussian:从单个 RGB 图像合成新视图的过程中直接建模 3D 高斯,打破像素或点云对应约束。
· HandOS:通过单一的处理阶段直接重建人手姿态,提高重建的准确性与效率。
01
传统强化学习方法在人-物交互(HOI)任务中依赖人工设计的技能特定奖励(Skill-specific Rewards),这类方法不仅耗时,且难以泛化到多样化的交互场景。尤其在篮球这类动态、多智能体、需精确协作的场景中,现有方法无法通过单一策略学习多种技能,也无法完成复杂的长时程任务。本文提出了一种 SkillMimic 的模仿学习框架,实现统一、可扩展的交互技能学习。
区别于传统方法,SkillMimic 的实现原理是基于数据驱动的模仿学习框架。该框架通过强化学习训练一个交互技能策略(Interaction Skill Policy),同时设计了统一的 HOI 模仿奖励函数,以模仿多样化的 HOI 状态转移。再训练一个高层控制器(High-Level Controller),复用学习到的交互技能来完成复杂任务。这使得 SkillMimic 无需为每个技能设计单独的奖励函数便能掌握多种交互技能,还能促进技能转换,降低工程成本的同时提高了学习效率。为解决传统方法中因接触建模不足导致的非自然运动问题,框架通过接触图奖励(Contact Graph Rewards)提高了交互的精确性和自然性。
SkillMimic 的效果示意图,能够学习包括投篮(蓝色)、运球(红色)、上篮和投篮(黄色)的基础动作以及会连续得分的复杂的动作(绿色)。
通过在两个不同的数据集 BallPlay-V 和 BallPlay-V 上进行测试,SkillMimic 在典型篮球技能(捡球、运球、上篮、投篮)的成功率均优于两种经典模仿学习方法 DeepMimic 和 AMP:SkillMimic 在需精确接触的任务(如捡球)中表现最优,成功率(86.7%)比 DeepMimic 高 4.4 倍,而 AMP 则为 0%。在高级篮球任务((投篮、带球、绕圈、得分)的对比中,SkillMimic 是唯一能完成复杂任务的方法,而传统方法 PPO、ASE 成功率均为 0%。同时随着数据规模的增长,SkillMimic 的多样性和泛化能力也会提高,并且技能切换和鲁棒性更强。
本研究为可扩展及可泛化的交互技能学习开辟了新方向,有望为机器人在不同领域,如家庭任务、其他体育项目等的实际应用提供思路。
本项工作获得今年的 Highlight,由香港科技大学、宇树科技、北京大学深圳研究生院、清华大学、IDEA 研究院、腾讯和卡内基梅隆大学共同完成。
02
从单目视频中重建高质量、可重光照的 3D 人头头像,是一项极具价值的任务。然而,由于单目输入的信息有限,加上头部姿态和面部运动的复杂性,使得任务变得极具挑战性。本文提出了 HRAvatar,这是一种基于 3D Gaussian Splatting 的方法,来弥补传统方法面临的问题。
HRAvatar 采用了可学习的形变表示和混合蒙皮策略,为每个高斯点独立学习形状和运动参数,使其能灵活适应不同人的独特面部变形,让重建的头像更加逼真和精细。再利用端到端表情编码器,通过训练直接优化表情参数,减少传统方法中基于伪标签(如 2D 关键点)的跟踪误差。为了支持实时重光照与材质编辑(分解反照率、粗糙度),HRAvatar 使用了基于物理的着色方式,增强了视觉效果的真实性和沉浸感。
通过输入单目视频,HRAvatar 能够重建出高质量且可动画的 3D 头像,并支持真实感重光照效果以及简单的材质编辑。
对比传统方法,HRAvatar 在 INSTA、HDTF 和自采集数据集上的实验证明了其在 PSNR、MAE、SSIM 和 LPIPS 等指标上具有显著优势。并且在自驱动、跨驱动和重光照任务中,HRAvatar 还原了更精细的纹理(如牙齿、毛发)和几何细节(如耳部)。
HRAvatar 可广泛应用于虚拟人、数字替身等高保真数字角色构建,适用于影视、游戏与元宇宙场景。它支持真实表情和光照还原,适合用于沉浸式 VR/AR 体验、个性化社交和远程通信。该技术还能赋能 AI 内容创作、自动动画生成等领域,降低成本同时提升交互真实感与表现力。
本项工作被 Photo-realistic 3D Head Avatars Workshop@CVPR25 邀请进行报告,由 IDEA 研究院和清华大学共同完成。
03
长时间序列的人体运动对于运动生成和理解等应用极具价值,但恢复这些运动极具挑战性。现有方法主要集中在单镜头视频上,或仅简化多镜头在相机空间中的对齐。本文提出了名为 HumanMM 的新框架,解决从包含多个镜头切换的野外视频中恢复世界坐标系下的 3D 人体运动的问题。
HumanMM 框架采用了镜头切换检测器识别视频中的镜头切换帧,确保了人体姿态和方向在世界坐标系下的准确性和时间一致性。同时使用双向 LSTM 基轨迹预测器和轨迹优化器,平滑人体姿态并缓解脚滑问题,使得运动的自然性得到提升。对比传统方法,HumanMM 通过增强的摄像机轨迹估计(Masked LEAP-VO)和人体运动对齐模块,提高了在多镜头视频中恢复人体运动的鲁棒性。
HumanMM 框架概览。顶部:我们以两个包含镜头切换的多镜头乒乓球比赛视频作为输入,目标是从两个视频中分别恢复两名运动员(马龙和樊振东)的动作。第一个视频由三个镜头(“①”、“②” 和 “③”)组成,第二个视频由两个镜头(“④” 和 “⑤”)恢复而成。底部:我们恢复了两名运动员的动作(马龙为绿色,樊振东为粉色),以及每个视频不同镜头和相机姿态下的运动。恢复的运动与视频中的运动对齐。
论文自建了一个基于现有的公共 3D 人体数据集 ms-Motion,将 HumanMM 和现有方法在 ROE(方向误差)、RTE(平移误差)、Jitter(抖动)、Foot Sliding(脚部滑动)等指标上进行对比。实验结果表明,HumanMM 的 PA-MPJPE(36.88 vs 基线 72.34)、RTE(2.56m vs 基线 9.62m)等指标显著优于现有方法 SLAHMR、WHAM 和 GVHMR。
该研究能推动 3D 人体运动恢复技术发展,还能提升计算机对复杂运动场景的理解,为体育、影视、游戏等多领域提供支持。
本项工作由清华大学、IDEA 研究院、约翰霍普金斯大学、芝加哥大学、香港科技大学和香港大学共同完成。
04
从单个 RGB 图像合成新视图的现有方法通常通过像素或点云对应关系来回归高斯分布,这会导致资源浪费且缺乏准确的几何和纹理。本文介绍了一种名为 LeanGaussian 的新方法,通过可变形 Transformer直接建模 3D 高斯,打破像素或点云对应约束。
LeanGaussian 的核心是将每个查询视为一个 3D 高斯椭球体,通过多层解码器迭代优化其参数,避免了因像素或点云对应关系导致的高斯分布过度使用。并且可以根据任务的需求任意调整模型复杂度,不仅提高了资源利用效率,也能在短时间内完成高质量的三维重建和渲染任务。同时,LeanGaussian 将每个高斯的 3D 中心投影到 2D 图像平面,作为可变形注意力机制的参考点,自动关联最相关的图像特征。这能够更准确地捕捉三维物体的几何形状和纹理信息,避免了过度拟合其他表示的问题。
(a) LeanGaussian 和现有方法的对比
(b) LeanGaussian 和现有方法在显存使用情况的对比
通过在 ShapeNet SRN 数据集和 Google Scanned Objects 数据集上进行验证,LeanGaussian 在两个数据集上分别以 25.44 和 22.36 的 PSNR 优于现有方法约 6.1%。此外,该方法在三维重建速度和渲染速度上也表现出色,分别达到 7.2 FPS 和 500 FPS。实验还表明,该方法在远离输入视图的视图上也具有良好的性能,相较于现有方法,其性能下降幅度较小。
未来,LeanGaussian 可以进一步优化以生成更复杂的场景和更精细的几何细节。同时,其在处理自遮挡和背景纹理生成方面的改进也为未来研究提供了方向。
本项工作由 IDEA 研究院、香港科技大学和香港中文大学(深圳)共同完成。
05
传统手部重建方法依赖多阶段流程,包括检测、左右手识别和姿态估计,存在冗余计算和累积误差问题。本文提出了一个用于 3D 手部重建的端到端框架 HandOS,创新性地将手部检测、2D 姿态估计和 3D 网格重建整合到一个单一的处理阶段中,从而避免了传统多阶段方法中的不足。
具体来说,HandOS 使用了冻结检测器作为基础来定位手部区域,通过“侧调谐”(Side Tuning)生成补充特征,保留检测能力的同时增强姿态语义。再通过交互式 2D-3D 解码器来同时学习 2D 和 3D 特征,这使得 HandOS 能够更准确地捕捉手部的几何结构和空间关系,简化了工作流程的同时减少了由于多阶段处理导致的误差累积,最终提高了重建的准确性。
HandOS,一种单阶段手部重建方法,显著简化了传统流程。此外,实验表明 HandOS 能有效适应多样化复杂场景(如遮挡、密集物体等),凸显其在实际应用中的高适用性。
HandOS 在多个公共基准测试中的评估验证了它在精度、鲁棒性、效率和泛化能力等多项指标上优于传统技术。
该方法可以运用于现实技术、行为理解、交互建模和具身智能等领域,对人体行为理解和机器人动作学习具有重要意义。
本项工作由北京大学工学院先进制造与机器人系、IDEA 研究院和中国科学院大学共同完成。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

