


2023 年 1 月,深度学习顶级学术会议 ICLR 2023 正式公布论文收录结果。IDEA 研究院计算机视觉与机器人研究中心(CVR)投稿论文均顺利获得收录,中稿率 100%!被收录的论文涵盖了目标检测、Transformer 模型训练、人体姿态估计等方向。
ICLR 全称为国际学习表征会议(International Conference on Learning Representations),由深度学习三大巨头的 Yoshua Bengio 和 Yann LeCun 牵头创办,是深度学习领域的顶级会议之一。在 Google Scholar 的学术会议/期刊排名中,ICLR 目前排名第 9 位。ICLR 2023 预计将于 5 月 1 日至 5 日在卢旺达首都基加利举办。
下面是入选论文概览:
论文链接:https://readpaper.com/paper/4599417873076592641
开源链接:https://github.com/IDEA-Research/DINO
目标检测是计算机视觉领域的基础任务,对于一张给定的图片,它要求模型能够找到并定位图片中的物体。这一任务极具挑战,被广泛应用于很多下游任务。基于 DETR 的检测方法是 Transformer 应用在目标检测中的成功范例,但是他们与经典的基于 CNN 的检测方法在检测性能和收敛速度上还有差距。本文提出的检测方法 DINO 基于前人的方法,通过对 denoising training, decoder 的梯度传递和 query selection 部分的优化,在 denoising 部分即使用了正样本(同 DN-DETR),又使用了 hard negative 的方式抑制重复框,在 decoder 的梯度传递时使用 look-forward-twice 的方法防止陷入局部最优解,用 mix-query-selection 的方法选择初始化的 anchors。DINO 取得了当时 COCO 榜单的第一名,第一次证明了基于 DETR 的检测模型具有超越经典方法的潜力。
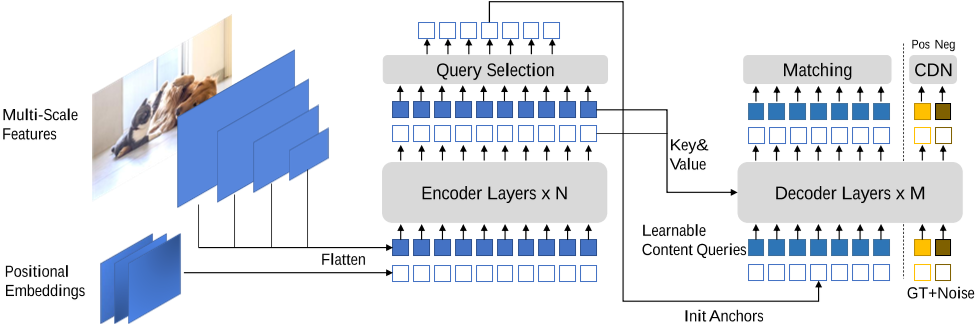
论文链接:https://readpaper.com/paper/717255664598069248
我们提出了一种利普希茨连续 Transformer,称为 LipsFormer,旨在从理论上和实证上追求 Transformer 模型的训练稳定性。与之前的通过改进学习率预热、层归一化、注意力表述和权重初始化来解决训练不稳定性的实际技巧不同,我们表明利普希茨连续性是确保训练稳定性的更重要的性质。在 LipsFormer 中,我们用利普希茨连续的模块替换不稳定的 Transformer 组件模块:具体的说,我们用 CenterNorm 代替 LayerNorm,谱初始化代替 Xavier 初始化,缩放余弦相似度注意力代替点积注意力,以及加权的残差模块替代原因残差结构。我们理论证明这些引入的模块是满足 Lipschitz 连续条件的并给出了对应的利普希茨常量,并对整个 LipsFormer 网络的利普希茨常数给出了一个上界。我们的实验表明,LipsFormer 允许深层 Transformer 架构的稳定训练,而不需要仔细的学习率调整(如预热),实现更快的收敛和更好的泛化。在 ImageNet 1K 数据集上,基于 Swin Transformer 训练 300 个周期的 LipsFormer-Swin-Tiny 可以在没有任何学习率预热的情况下获得 82.7%的准确率。此外,基于 CSwin 的 LipsFormer-CSwin-Tiny 在 300 个周期的训练中可以获得 83.5%的 Top-1 准确率。
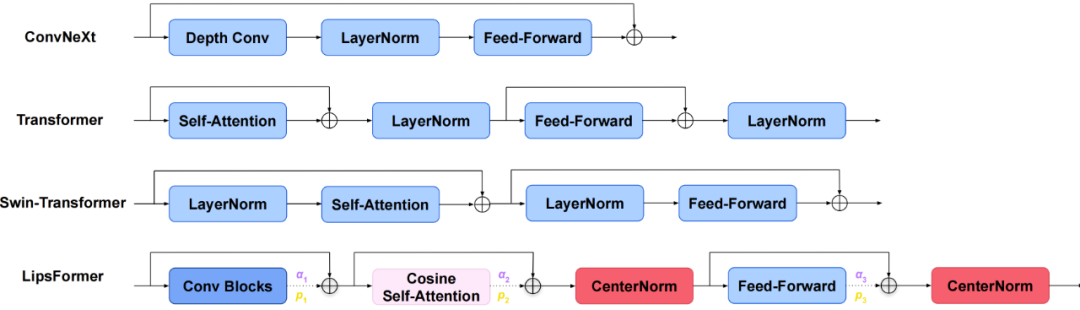
论文链接:https://readpaper.com/paper/4720151013491752961
开源链接:https://github.com/IDEA-Research/ED-Pose
多人姿态估计旨在定位目标图像中每个人的 2D 关键点位置,其被广泛应用于增强现实(AR)、虚拟现实(VR),人机交互(HCI)等领域。ED-Pose 提出了一种具有显式框检测的端到端多人姿态估计框架。与先前的单阶段方法不同,ED-Pose 将多人姿态估计重新定义为两个具有统一表示和回归监督的显式框检测过程。具体而言,ED-Pose 首先利用一个人体检测解码器为后续关键点检测提供一个良好的初始化,从而加快训练收敛。为了引入关键点附近的上下文信息,ED-Pose 将姿势估计视为关键点框检测问题,以学习每个关键点的框位置和内部特征。此外,ED-Pose 采用人体与关键点特征交互学习策略来增强全局和局部特征聚合。总的来说,ED-Pose 概念简单,无需后处理和热图监督。实验结果表明,显式框检测将姿势估计性能在 COCO 数据集和 CrowdPose 数据集上分别提高了 4.5 AP 和 9.9 AP。这也是首次,ED-Pose 作为一个只有 L1 loss 的完全端到端框架能在 COCO 数据集上优于基于热图的自上而下方法 1.2 AP,并以 76.6 AP 达到 CrowdPose 数据集上的 SOTA。
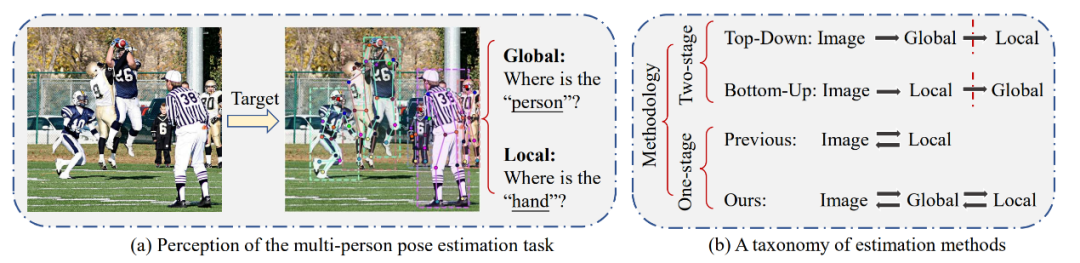
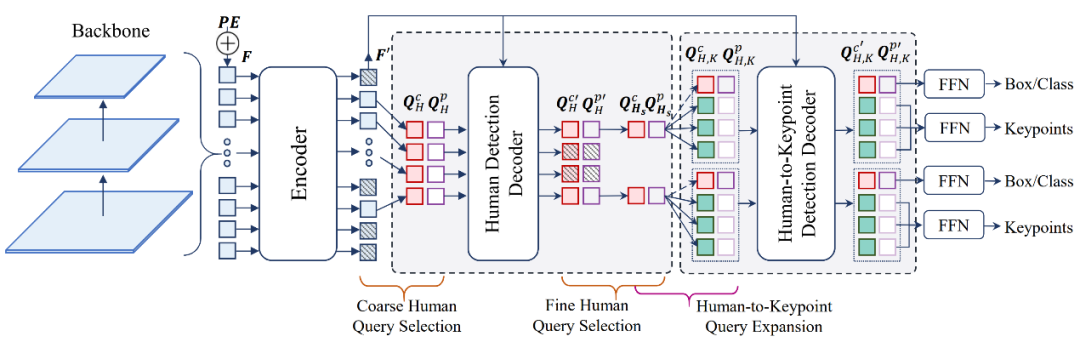
2023 年 1 月,深度学习顶级学术会议 ICLR 2023 正式公布论文收录结果。IDEA 研究院计算机视觉与机器人研究中心(CVR)投稿论文均顺利获得收录,中稿率 100%!被收录的论文涵盖了目标检测、Transformer 模型训练、人体姿态估计等方向。
ICLR 全称为国际学习表征会议(International Conference on Learning Representations),由深度学习三大巨头的 Yoshua Bengio 和 Yann LeCun 牵头创办,是深度学习领域的顶级会议之一。在 Google Scholar 的学术会议/期刊排名中,ICLR 目前排名第 9 位。ICLR 2023 预计将于 5 月 1 日至 5 日在卢旺达首都基加利举办。
下面是入选论文概览:
论文链接:https://readpaper.com/paper/4599417873076592641
开源链接:https://github.com/IDEA-Research/DINO
目标检测是计算机视觉领域的基础任务,对于一张给定的图片,它要求模型能够找到并定位图片中的物体。这一任务极具挑战,被广泛应用于很多下游任务。基于 DETR 的检测方法是 Transformer 应用在目标检测中的成功范例,但是他们与经典的基于 CNN 的检测方法在检测性能和收敛速度上还有差距。本文提出的检测方法 DINO 基于前人的方法,通过对 denoising training, decoder 的梯度传递和 query selection 部分的优化,在 denoising 部分即使用了正样本(同 DN-DETR),又使用了 hard negative 的方式抑制重复框,在 decoder 的梯度传递时使用 look-forward-twice 的方法防止陷入局部最优解,用 mix-query-selection 的方法选择初始化的 anchors。DINO 取得了当时 COCO 榜单的第一名,第一次证明了基于 DETR 的检测模型具有超越经典方法的潜力。
论文链接:https://readpaper.com/paper/717255664598069248
我们提出了一种利普希茨连续 Transformer,称为 LipsFormer,旨在从理论上和实证上追求 Transformer 模型的训练稳定性。与之前的通过改进学习率预热、层归一化、注意力表述和权重初始化来解决训练不稳定性的实际技巧不同,我们表明利普希茨连续性是确保训练稳定性的更重要的性质。在 LipsFormer 中,我们用利普希茨连续的模块替换不稳定的 Transformer 组件模块:具体的说,我们用 CenterNorm 代替 LayerNorm,谱初始化代替 Xavier 初始化,缩放余弦相似度注意力代替点积注意力,以及加权的残差模块替代原因残差结构。我们理论证明这些引入的模块是满足 Lipschitz 连续条件的并给出了对应的利普希茨常量,并对整个 LipsFormer 网络的利普希茨常数给出了一个上界。我们的实验表明,LipsFormer 允许深层 Transformer 架构的稳定训练,而不需要仔细的学习率调整(如预热),实现更快的收敛和更好的泛化。在 ImageNet 1K 数据集上,基于 Swin Transformer 训练 300 个周期的 LipsFormer-Swin-Tiny 可以在没有任何学习率预热的情况下获得 82.7%的准确率。此外,基于 CSwin 的 LipsFormer-CSwin-Tiny 在 300 个周期的训练中可以获得 83.5%的 Top-1 准确率。
论文链接:https://readpaper.com/paper/4720151013491752961
开源链接:https://github.com/IDEA-Research/ED-Pose
多人姿态估计旨在定位目标图像中每个人的 2D 关键点位置,其被广泛应用于增强现实(AR)、虚拟现实(VR),人机交互(HCI)等领域。ED-Pose 提出了一种具有显式框检测的端到端多人姿态估计框架。与先前的单阶段方法不同,ED-Pose 将多人姿态估计重新定义为两个具有统一表示和回归监督的显式框检测过程。具体而言,ED-Pose 首先利用一个人体检测解码器为后续关键点检测提供一个良好的初始化,从而加快训练收敛。为了引入关键点附近的上下文信息,ED-Pose 将姿势估计视为关键点框检测问题,以学习每个关键点的框位置和内部特征。此外,ED-Pose 采用人体与关键点特征交互学习策略来增强全局和局部特征聚合。总的来说,ED-Pose 概念简单,无需后处理和热图监督。实验结果表明,显式框检测将姿势估计性能在 COCO 数据集和 CrowdPose 数据集上分别提高了 4.5 AP 和 9.9 AP。这也是首次,ED-Pose 作为一个只有 L1 loss 的完全端到端框架能在 COCO 数据集上优于基于热图的自上而下方法 1.2 AP,并以 76.6 AP 达到 CrowdPose 数据集上的 SOTA。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

