


编者按:目标检测是计算机视觉领域的重要任务之一,在日常生活中我们不难接触到它,例如自动驾驶、人脸识别、机器人运动、医疗检测等应用场景中,都涉及大量需要检测定位物体的情况。持续优化目标检测模型、提升检测性能,是这一领域研究者不断努力的事情。
IDEA 研究院入选 ICLR 2023 的论文之一“DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection”,针对 DETR 模型的 pipeline 提出三点改进方法,大幅提升模型性能至 SOTA(State-of-the-Art,即最好性能),成为第一个在 COCO 目标检测上取得榜单第一的 DETR 类模型。相比之前取得 SOTA 的检测器,DINO 更是将模型参数和训练数据减少了十倍以上。
本期带你详细了解 DINO 的系列工作及研究思考。文末短视频栏目“科研有门道”邀请到作者分享写好科研论文的心得 tips,可不要错过噢!
详细了解论文内容前
先看看 DINO 检测效果怎么样
人群拥挤密集的游乐园,担心小朋友走丢?
画面再远、人物再小,也能实现快速精准定位

街头场景复杂多变,人潮车流穿梭不息
检测框也能丝滑地紧“跟”上你的脚步


近年来,人工智能领域内的模型设计越来越统一,Transformer 凭借其通用的结构、高效的设计,不仅主导了自然语言处理(NLP)领域,以 ViT 为代表的工作更是将其成功推广到了视觉骨干领域,成为大一统文本、图像和语音领域算法的可能。
2021 年,Transformer 在视觉领域取得了又一巨大成果,微软亚洲研究院(MSRA)提出的 Swin-Transformer 系列工作,将构建在 Swin-L 上的 Dynamic Head 的准确度首次达至 60 以上。然而,由于数据规模、模型大小已逼近当时极限,此后想通过数据或规模实现模型的任一细小提升,都变得非常困难。
在目标检测领域,经典的检测器大都基于卷积网络(CNN)进行设计和改进,比如 Faster RCNN、YOLO 等,在 COCO 目标检测榜单上,多数方法也是基于 CNN 的检测头。不过,传统检测器虽然处于“统治”地位,但其方法往往包含繁琐、需手工设计的模块,且模型非常庞大,复杂的模型结构往往限制了模型规模的扩大,也不利于算法和结构的改进。

DETR 类检测器完全使用 Transformer 结构代替了传统的检测头,将目标检测建模成集合预测问题,为这一领域提供了一种全新的检测思路,并大大简化了检测模型的结构,使得模型提升的空间得以增加。但其收敛速度慢、性能不佳、query 不可解释等问题一直饱受诟病。尽管后续有诸多改进工作,如 Deformable DETR、Conditional DETR 等尝试从不同角度提供解法,但仍未取得超越经典检测器的检测性能。
方法新颖、设计简洁且端到端可学习的 DETR 类检测器,是否还有办法取得更好的表现?它有无可能成为目标检测领域的新主流,得到更为广泛的运用?研究团队提出的 DINO 方法,对这些问题给出了肯定的答案。
提出 DINO 之前,研究团队在优化 DETR 类模型的工作上已取得不少成绩,包括入选 ICLR 2022 的 DAB-DETR[1]和获 CVPR 2022 收录为 Oral 论文的 DN-DETR[2]。
基于两项工作的思路,DINO 针对模型的整个 pipeline 提出三点改进,从多个角度的优化实现了模型性能的大幅提升,达至 SOTA。后续也已被不少工作参考和使用,并被拓展至图像分割(如 Mask DINO)等任务领域。

具体来看,DINO 系列工作如何一步步实现模型提升呢?
研究团队首先认为,经典的检测方法经过多年研究后,其 pipline 得到了高度优化,而 DETR 类模型诞生不久,基于它的方法还没有得到好的优化。想要公平地比较两种方法的效果,需要对 DETR 类模型优化整个 pipline,建立起一个性能强的基准模型(baseline)。
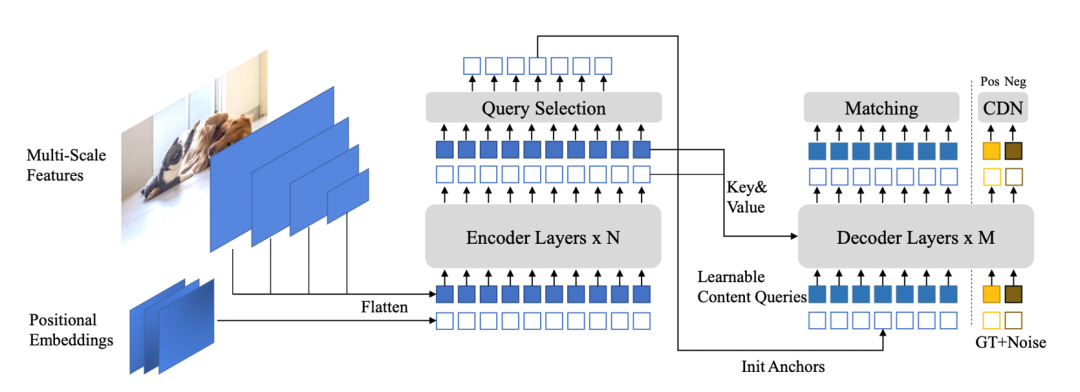
原始的 DETR 模型一直存在 positional query 无明确含义、全局搜索难和二分图匹配不稳定等问题。第一项工作 DAB-DETR 针对理解模型 query 的问题,提出了显式地用四维的、可学习的 anchor box 作为 query,让模型得到更加精确的检测框预测结果,并通过动态更新来帮助 decoder cross-attention 抽取特征,最终为模型带来更好的可解释性及更快的收敛速度。
第二项工作 DN-DETR 分析了 DETR 中全局搜索难和二分图匹配不稳定导致模型收敛慢的问题,提出了一种新的去噪训练方法,一是选择加了噪声的真实框,让模型学习重建真实框,二是加入一个去噪任务直接把带有噪声的真实框输入到 decoder 中,跳过原本的匹配过程直接进行学习,最终提升训练稳定性以及进一步加快收敛速度。
沿着前两项工作,研究团队进一步思考两个问题:一是 DAB-DETR 让人们意识到 query 的重要性,接下来如何让模型学到更好的或者初始化更好的 query?二是 DN-DETR 引入了去噪训练来稳定标签分配,是否还可以进一步优化标签分配?
基于此,研究团队在 DINO 的设计中提出了三点改进工作,分别是:
1.Contrastive denoising:在去噪训练中设计了让模型识别负样本的方法,通过对比学习负样本 anchor box 与加了较小噪声的正样本,不仅让模型学会选择较好的 anchor box,也可以减少重复预测;
2.Mix query selection:选取信息最明显的一些图片特征,并将其位置作为 anchor box 的初始化,进一步加速了模型收敛;
3.Look forward twice(涉及梯度传递,详细介绍可阅读原文了解)
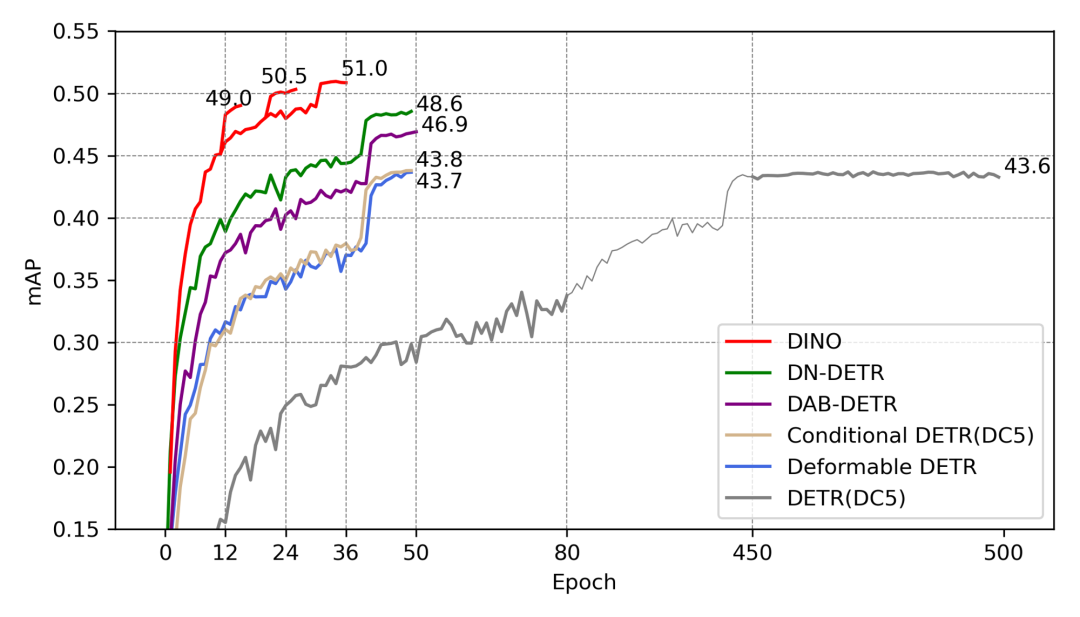
研究团队将基于 ResNet50 backbone 的 DINO 模型,分别在 12 epoch setting 和 50 epoch setting 与其他基准模型的方法进行比较:在 12 epoch setting 上,DINO 性能显著超过其他方法,较第二名提升了 5.6AP;在 50 epoch setting 上,DINO 36 epoch 取得的表现同样远超其他方法。
在 COCO 榜单上,将 DINO 基于 Swin-L backbone 的模型与其他方法进行比较,可以我们超越了前面所有方法,比如 SwinL (HTC++)。此外,与其他方法相比,DINO 使用了更小的模型和更少的数据量即取得了最好的结果。
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
论文地址:https://readpaper.com/paper/4599417873076592641
代码地址:https://github.com/IDEA-Research/DINO
[1] Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. DAB-DETR: Dynamic anchor boxes are better queries for DETR. arXiv preprint arXiv:2201.12329, 2022.
[2] Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. DN-DETR: Accelerate DETR training by introducing query denoising. arXiv preprint arXiv:2203.01305, 2022.
编者按:目标检测是计算机视觉领域的重要任务之一,在日常生活中我们不难接触到它,例如自动驾驶、人脸识别、机器人运动、医疗检测等应用场景中,都涉及大量需要检测定位物体的情况。持续优化目标检测模型、提升检测性能,是这一领域研究者不断努力的事情。
IDEA 研究院入选 ICLR 2023 的论文之一“DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection”,针对 DETR 模型的 pipeline 提出三点改进方法,大幅提升模型性能至 SOTA(State-of-the-Art,即最好性能),成为第一个在 COCO 目标检测上取得榜单第一的 DETR 类模型。相比之前取得 SOTA 的检测器,DINO 更是将模型参数和训练数据减少了十倍以上。
本期带你详细了解 DINO 的系列工作及研究思考。文末短视频栏目“科研有门道”邀请到作者分享写好科研论文的心得 tips,可不要错过噢!
详细了解论文内容前
先看看 DINO 检测效果怎么样
人群拥挤密集的游乐园,担心小朋友走丢?
画面再远、人物再小,也能实现快速精准定位
街头场景复杂多变,人潮车流穿梭不息
检测框也能丝滑地紧“跟”上你的脚步
近年来,人工智能领域内的模型设计越来越统一,Transformer 凭借其通用的结构、高效的设计,不仅主导了自然语言处理(NLP)领域,以 ViT 为代表的工作更是将其成功推广到了视觉骨干领域,成为大一统文本、图像和语音领域算法的可能。
2021 年,Transformer 在视觉领域取得了又一巨大成果,微软亚洲研究院(MSRA)提出的 Swin-Transformer 系列工作,将构建在 Swin-L 上的 Dynamic Head 的准确度首次达至 60 以上。然而,由于数据规模、模型大小已逼近当时极限,此后想通过数据或规模实现模型的任一细小提升,都变得非常困难。
在目标检测领域,经典的检测器大都基于卷积网络(CNN)进行设计和改进,比如 Faster RCNN、YOLO 等,在 COCO 目标检测榜单上,多数方法也是基于 CNN 的检测头。不过,传统检测器虽然处于“统治”地位,但其方法往往包含繁琐、需手工设计的模块,且模型非常庞大,复杂的模型结构往往限制了模型规模的扩大,也不利于算法和结构的改进。
DETR 类检测器完全使用 Transformer 结构代替了传统的检测头,将目标检测建模成集合预测问题,为这一领域提供了一种全新的检测思路,并大大简化了检测模型的结构,使得模型提升的空间得以增加。但其收敛速度慢、性能不佳、query 不可解释等问题一直饱受诟病。尽管后续有诸多改进工作,如 Deformable DETR、Conditional DETR 等尝试从不同角度提供解法,但仍未取得超越经典检测器的检测性能。
方法新颖、设计简洁且端到端可学习的 DETR 类检测器,是否还有办法取得更好的表现?它有无可能成为目标检测领域的新主流,得到更为广泛的运用?研究团队提出的 DINO 方法,对这些问题给出了肯定的答案。
提出 DINO 之前,研究团队在优化 DETR 类模型的工作上已取得不少成绩,包括入选 ICLR 2022 的 DAB-DETR[1]和获 CVPR 2022 收录为 Oral 论文的 DN-DETR[2]。
基于两项工作的思路,DINO 针对模型的整个 pipeline 提出三点改进,从多个角度的优化实现了模型性能的大幅提升,达至 SOTA。后续也已被不少工作参考和使用,并被拓展至图像分割(如 Mask DINO)等任务领域。
具体来看,DINO 系列工作如何一步步实现模型提升呢?
研究团队首先认为,经典的检测方法经过多年研究后,其 pipline 得到了高度优化,而 DETR 类模型诞生不久,基于它的方法还没有得到好的优化。想要公平地比较两种方法的效果,需要对 DETR 类模型优化整个 pipline,建立起一个性能强的基准模型(baseline)。
原始的 DETR 模型一直存在 positional query 无明确含义、全局搜索难和二分图匹配不稳定等问题。第一项工作 DAB-DETR 针对理解模型 query 的问题,提出了显式地用四维的、可学习的 anchor box 作为 query,让模型得到更加精确的检测框预测结果,并通过动态更新来帮助 decoder cross-attention 抽取特征,最终为模型带来更好的可解释性及更快的收敛速度。
第二项工作 DN-DETR 分析了 DETR 中全局搜索难和二分图匹配不稳定导致模型收敛慢的问题,提出了一种新的去噪训练方法,一是选择加了噪声的真实框,让模型学习重建真实框,二是加入一个去噪任务直接把带有噪声的真实框输入到 decoder 中,跳过原本的匹配过程直接进行学习,最终提升训练稳定性以及进一步加快收敛速度。
沿着前两项工作,研究团队进一步思考两个问题:一是 DAB-DETR 让人们意识到 query 的重要性,接下来如何让模型学到更好的或者初始化更好的 query?二是 DN-DETR 引入了去噪训练来稳定标签分配,是否还可以进一步优化标签分配?
基于此,研究团队在 DINO 的设计中提出了三点改进工作,分别是:
1.Contrastive denoising:在去噪训练中设计了让模型识别负样本的方法,通过对比学习负样本 anchor box 与加了较小噪声的正样本,不仅让模型学会选择较好的 anchor box,也可以减少重复预测;
2.Mix query selection:选取信息最明显的一些图片特征,并将其位置作为 anchor box 的初始化,进一步加速了模型收敛;
3.Look forward twice(涉及梯度传递,详细介绍可阅读原文了解)
研究团队将基于 ResNet50 backbone 的 DINO 模型,分别在 12 epoch setting 和 50 epoch setting 与其他基准模型的方法进行比较:在 12 epoch setting 上,DINO 性能显著超过其他方法,较第二名提升了 5.6AP;在 50 epoch setting 上,DINO 36 epoch 取得的表现同样远超其他方法。
在 COCO 榜单上,将 DINO 基于 Swin-L backbone 的模型与其他方法进行比较,可以我们超越了前面所有方法,比如 SwinL (HTC++)。此外,与其他方法相比,DINO 使用了更小的模型和更少的数据量即取得了最好的结果。
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
论文地址:https://readpaper.com/paper/4599417873076592641
代码地址:https://github.com/IDEA-Research/DINO
[1] Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. DAB-DETR: Dynamic anchor boxes are better queries for DETR. arXiv preprint arXiv:2201.12329, 2022.
[2] Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. DN-DETR: Accelerate DETR training by introducing query denoising. arXiv preprint arXiv:2203.01305, 2022.





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

