


继去年 11 月在 2023 IDEA 大会上推出基于视觉提示的开集检测模型 T-Rex 后,IDEA 研究院团队又携重磅新作归来:视觉与文本提示相互融合,打造超强跨图能力,向通用目标检测更进一步!
T-Rex2 具有超强的跨帧与跨图检测能力,只需在一张图片或帧上进行视觉提示,就能在其他图片上进行检测。
拉框、检测、完成!在实际工业应用中,常见的需求是在⼀张或多张图像上进行视觉提示,然后在其他图像上使用这个视觉提示进行检测。这个即是跨图检测能力。
这个关键能力,让目标检测技术在生产生活中可以真正开始广泛应用。如工业生产流水线器件检测,交通航运领域的船舶、飞机检测,农业领域的农作物、果蔬检测,生物医学领域的细胞、组织检测,物流领域的货物检测,环境领域的野生动物监测等。
IDEA 研究院 CVR 团队最新发布 T-Rex2 模型,通过视觉与文本提示的互相融合,弥补视觉提示的一些关键缺陷,实现流畅可用的跨图目标检测。与多目标跟踪模型结合后,T-Rex2 还可以轻松应用于各种视频检测任务。
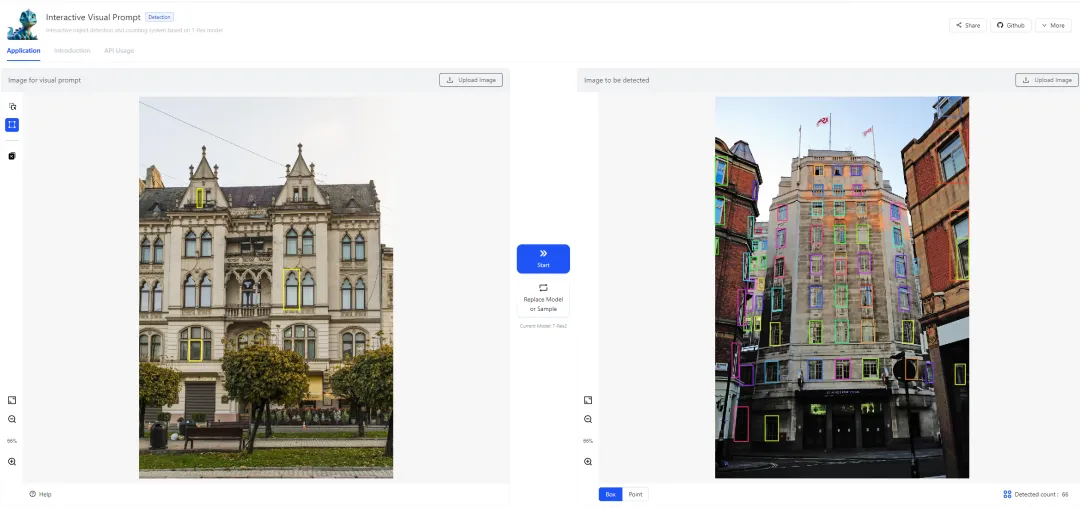 T-Rex2 图像检测应用展示。
T-Rex2 图像检测应用展示。
 T-Rex2 视频检测应用展示。
T-Rex2 视频检测应用展示。
文本与视觉提示融合
在开集目标检测领域,利用文本提示进行开放词汇目标检测已是⼀种流行做法。尽管文本提示受到广泛青睐,但它仍有一些局限性:
►长尾数据短缺。文本提示的训练需要和视觉模态之间的模态对齐,但长尾对象(即稀有或者全新的物体类别)的数据稀缺可能会削弱其学习效率。
►描述上的局限性。对于一些难以用语言描绘的对象,因受限于无法精确描述,也会削弱文本提示的效果。比如对于一些细菌或者微生物,如果没有专业的领域知识,用户是无法用文本来进行准确描绘的。
 文本提示示意
文本提示示意
相反,视觉提示提供了一种更直观、更直接的对象表示方法。例如,即使用户不知道待检测目标的类别或名称,也可以使用点或框来标记待检测的对象。然而,视觉提示也有其局限性。与文本提示相比,它们在捕捉常见对象的概念时效果较差。
例如,在文本提示里,“狗”这个字已经可以广泛涵盖所有狗的品种。相比之下,对于视觉提示,需要有多样化的狗的照片,体现不同的品种、大小和颜色等等,才能完整地传达“狗”这个概念。
 视觉提示示意
视觉提示示意
T-Rex2 通过在一个模型中同时整合文本和视觉提示,克服了这两种提示模态各自的局限,并利用了两种模态的优势。
文本和视觉提示的协同作用赋予了 T-Rex2 强大的跨图检测能力和零样本能力。
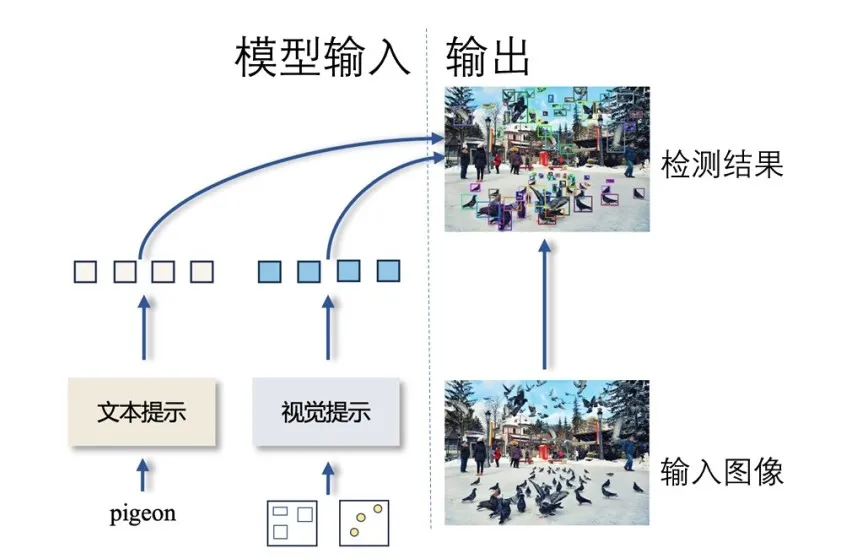
T-Rex2 模型结构简化图
在跨图检测任务中,T-Rex2 可以在一张图像上进行视觉提示,然后在其他图像上使用这个视觉提示进行检测。这种能力使得 T-Rex2 在实际应用中更加灵活,能够适应更多的检测场景。
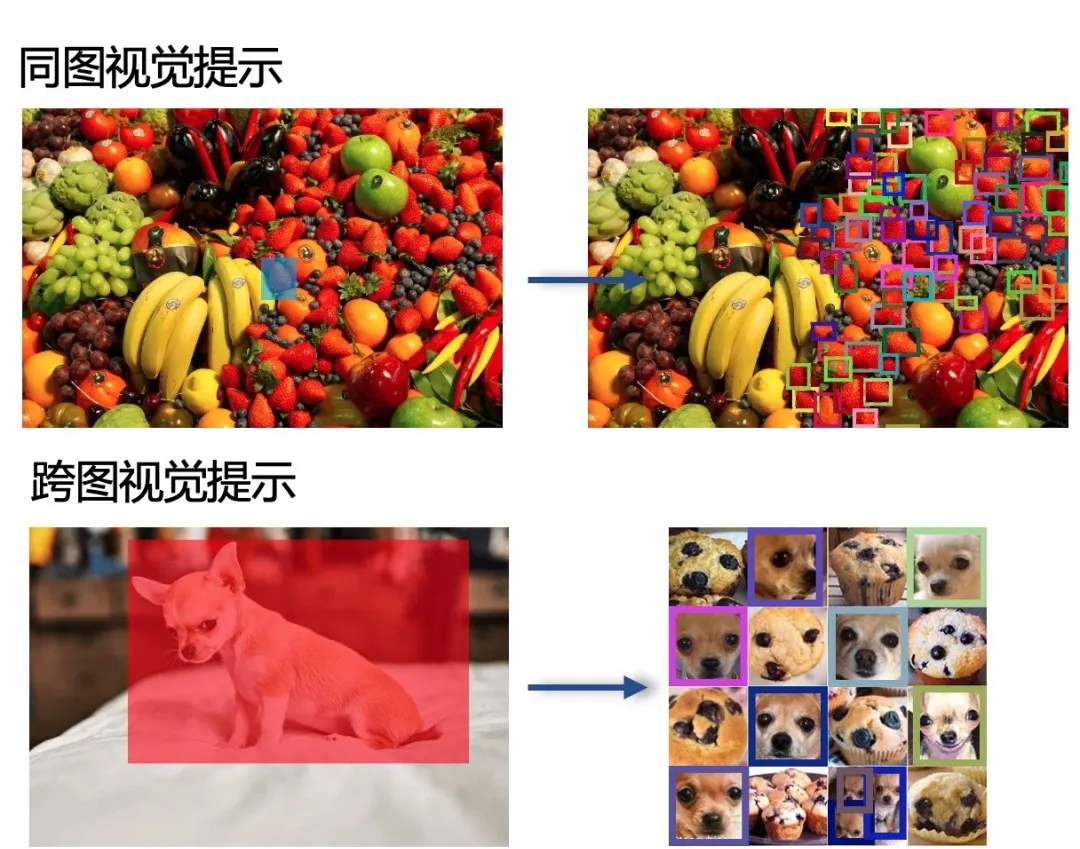
同图识别(Intra-image recognition)是指在单个图像内部识别和分类对象的任务。跨图识别(Inter-image recognition)是指在多个图像之间识别相同或不同对象的任务。
同图识别需要算法能够准确地在复杂的环境中识别和分割多个对象,而跨图识别则需要算法具备更强的泛化能力和对细节的敏感度,以便在不同的图像条件下识别和比较对象。
 T-Rex2 跨图检测能力示例。
T-Rex2 跨图检测能力示例。
支持多种工作模式
►文本提示模式:完全依靠文本提示进行物体检测,与开放词汇物体检测的方法相同。这适合于常见物体的检测。

►交互式视觉提示模式:用户与模型直接互动,即是“human in the loop”的概念。比如可以自己画点、画框来标记检测物体,然后根据模型输出的反馈来修正检测结果,如增加额外的提示。这是近年较为新颖的模式。

►通用视觉提示模式:用户可以通过向模型提供任意数量的示例图片来自定义特定对象的视觉嵌入,然后使用这个嵌入来检测任意图像中的对象,是不需要“human in the loop”。

4 个零样本 SOTA
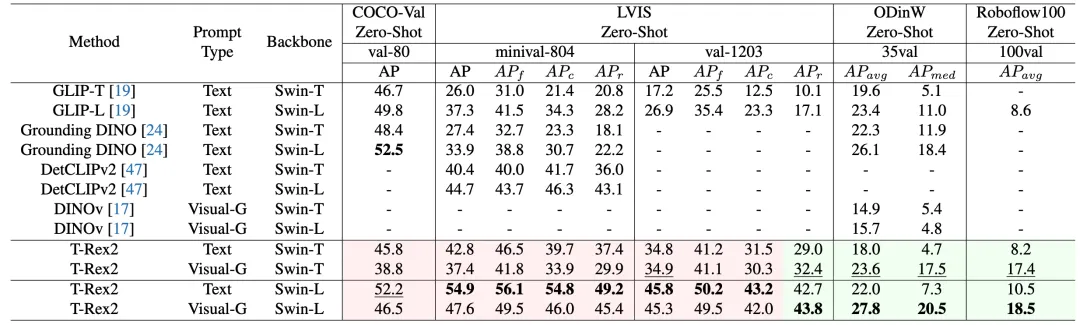 T-Rex2 性能表现
T-Rex2 性能表现
T-Rex2 在四个学术基准测试集 COCO, LVIS, ODinW, 和 Roboflow100 上取得了 Zero-Shot SOTA的性能。从指标上来看,文本提示和视觉提示分别在不同的场景下表现优异。
文本提示在相对常见类别的场景中表现优异,而视觉提示在长尾分布的场景中表现更加稳健。这也说明将这两种提示模态结合起来,能让模型更好地适应不同的场景。
开箱即用
T-Rex2 具备极强的开箱即用特性,无需重新训练或微调,即可检测模型在训练阶段从未见过的物体。该模型不仅可应用于包括计数在内的所有检测类任务,还为智能交互标注领域提供新的解决方案。
 T-Rex2 在各种应⽤场景下的检测效果
T-Rex2 在各种应⽤场景下的检测效果
T-Rex2 还可用于视频目标跟踪。在 T-Rex2 跨图逐帧的检测结果上,我们可以用现有的多目标跟踪模型( 如 ByteTrack ) 追踪检测物体。这让 T-Rex2 可以轻松应用于各种视频检测任务。
 T-Rex2 视频检测能力示例。
T-Rex2 视频检测能力示例。
T-Rex2 标志着我们向通用物体检测又迈出了新的一步。
想试玩吗?点击playground 链接!
现在,我们向公众开放了T-Rex2 API,欢迎您用 T-Rex2 构建出创新的应用。
有关 T-Rex2 的技术细节,请参考同期发布的论文。
点击阅读官方 technical blog。
本项工作来自 IDEA 研究院计算机视觉与机器人研究中心(CVR,Computer Vision and Robotics)。该团队此前开源的目标检测模型 DINO 是首个在 COCO 目标检测上取得榜单第一的 DETR 类模型;在 Github 上大火的零样本检测器 Grounding DINO 与能够检测、分割一切的 Grounded SAM,同样为该团队作品。
继去年 11 月在 2023 IDEA 大会上推出基于视觉提示的开集检测模型 T-Rex 后,IDEA 研究院团队又携重磅新作归来:视觉与文本提示相互融合,打造超强跨图能力,向通用目标检测更进一步!
T-Rex2 具有超强的跨帧与跨图检测能力,只需在一张图片或帧上进行视觉提示,就能在其他图片上进行检测。
拉框、检测、完成!在实际工业应用中,常见的需求是在⼀张或多张图像上进行视觉提示,然后在其他图像上使用这个视觉提示进行检测。这个即是跨图检测能力。
这个关键能力,让目标检测技术在生产生活中可以真正开始广泛应用。如工业生产流水线器件检测,交通航运领域的船舶、飞机检测,农业领域的农作物、果蔬检测,生物医学领域的细胞、组织检测,物流领域的货物检测,环境领域的野生动物监测等。
IDEA 研究院 CVR 团队最新发布 T-Rex2 模型,通过视觉与文本提示的互相融合,弥补视觉提示的一些关键缺陷,实现流畅可用的跨图目标检测。与多目标跟踪模型结合后,T-Rex2 还可以轻松应用于各种视频检测任务。
T-Rex2 图像检测应用展示。
T-Rex2 视频检测应用展示。
文本与视觉提示融合
在开集目标检测领域,利用文本提示进行开放词汇目标检测已是⼀种流行做法。尽管文本提示受到广泛青睐,但它仍有一些局限性:
►长尾数据短缺。文本提示的训练需要和视觉模态之间的模态对齐,但长尾对象(即稀有或者全新的物体类别)的数据稀缺可能会削弱其学习效率。
►描述上的局限性。对于一些难以用语言描绘的对象,因受限于无法精确描述,也会削弱文本提示的效果。比如对于一些细菌或者微生物,如果没有专业的领域知识,用户是无法用文本来进行准确描绘的。
文本提示示意
相反,视觉提示提供了一种更直观、更直接的对象表示方法。例如,即使用户不知道待检测目标的类别或名称,也可以使用点或框来标记待检测的对象。然而,视觉提示也有其局限性。与文本提示相比,它们在捕捉常见对象的概念时效果较差。
例如,在文本提示里,“狗”这个字已经可以广泛涵盖所有狗的品种。相比之下,对于视觉提示,需要有多样化的狗的照片,体现不同的品种、大小和颜色等等,才能完整地传达“狗”这个概念。
视觉提示示意
T-Rex2 通过在一个模型中同时整合文本和视觉提示,克服了这两种提示模态各自的局限,并利用了两种模态的优势。
文本和视觉提示的协同作用赋予了 T-Rex2 强大的跨图检测能力和零样本能力。
T-Rex2 模型结构简化图
在跨图检测任务中,T-Rex2 可以在一张图像上进行视觉提示,然后在其他图像上使用这个视觉提示进行检测。这种能力使得 T-Rex2 在实际应用中更加灵活,能够适应更多的检测场景。
同图识别(Intra-image recognition)是指在单个图像内部识别和分类对象的任务。跨图识别(Inter-image recognition)是指在多个图像之间识别相同或不同对象的任务。
同图识别需要算法能够准确地在复杂的环境中识别和分割多个对象,而跨图识别则需要算法具备更强的泛化能力和对细节的敏感度,以便在不同的图像条件下识别和比较对象。
T-Rex2 跨图检测能力示例。
支持多种工作模式
►文本提示模式:完全依靠文本提示进行物体检测,与开放词汇物体检测的方法相同。这适合于常见物体的检测。
►交互式视觉提示模式:用户与模型直接互动,即是“human in the loop”的概念。比如可以自己画点、画框来标记检测物体,然后根据模型输出的反馈来修正检测结果,如增加额外的提示。这是近年较为新颖的模式。
►通用视觉提示模式:用户可以通过向模型提供任意数量的示例图片来自定义特定对象的视觉嵌入,然后使用这个嵌入来检测任意图像中的对象,是不需要“human in the loop”。
4 个零样本 SOTA
T-Rex2 性能表现
T-Rex2 在四个学术基准测试集 COCO, LVIS, ODinW, 和 Roboflow100 上取得了 Zero-Shot SOTA的性能。从指标上来看,文本提示和视觉提示分别在不同的场景下表现优异。
文本提示在相对常见类别的场景中表现优异,而视觉提示在长尾分布的场景中表现更加稳健。这也说明将这两种提示模态结合起来,能让模型更好地适应不同的场景。
开箱即用
T-Rex2 具备极强的开箱即用特性,无需重新训练或微调,即可检测模型在训练阶段从未见过的物体。该模型不仅可应用于包括计数在内的所有检测类任务,还为智能交互标注领域提供新的解决方案。
T-Rex2 在各种应⽤场景下的检测效果
T-Rex2 还可用于视频目标跟踪。在 T-Rex2 跨图逐帧的检测结果上,我们可以用现有的多目标跟踪模型( 如 ByteTrack ) 追踪检测物体。这让 T-Rex2 可以轻松应用于各种视频检测任务。
T-Rex2 视频检测能力示例。
T-Rex2 标志着我们向通用物体检测又迈出了新的一步。
想试玩吗?点击playground 链接!
现在,我们向公众开放了T-Rex2 API,欢迎您用 T-Rex2 构建出创新的应用。
有关 T-Rex2 的技术细节,请参考同期发布的论文。
点击阅读官方 technical blog。
本项工作来自 IDEA 研究院计算机视觉与机器人研究中心(CVR,Computer Vision and Robotics)。该团队此前开源的目标检测模型 DINO 是首个在 COCO 目标检测上取得榜单第一的 DETR 类模型;在 Github 上大火的零样本检测器 Grounding DINO 与能够检测、分割一切的 Grounded SAM,同样为该团队作品。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

