


国际顶级学术会议 CVPR 2023 近日公布论文收录结果,IDEA 研究院 8 篇研究工作入选,涵盖了目标检测、图像分割等计算机视觉领域的重要任务以及多模态语义理解等领域,在 3D 人体姿态估计、轻量级模型设计、高效 CLIP 训练策略、多画风数据集等取得了新的进展。
CVPR 全称为 IEEE 国际计算机视觉与模式识别会议,在 Google Scholar 的学术会议/期刊排名中目前位列第 4。CVPR 2023 投稿论文 9155 篇中共收录 2360 篇,录取率为 25.78%,会议预计将于 6 月 18 日至 22 日在加拿大温哥华举办。
欢迎跟随本期文章,了解 IDEA 研究院在计算机视觉领域的部分最新学术成果。

统一的检测和分割框架,简洁高效,SOTA 性能。
摘要:在本文中,我们介绍了 Mask DINO,一个统一的目标检测和分割框架。Mask DINO 通过添加支持所有图像分割任务(实例、全景和语义)的分割预测分支扩展了 DINO(DETR with Improved Denoising Anchor Boxes)。它利用来自 DINO 的查询嵌入对高分辨率像素嵌入图进行点积,以预测一组二进制分割。DINO 中的一些关键组件通过共享架构和训练过程进行了扩展以进行分割。Mask DINO 简单、高效且可扩展,并且可以受益于联合大规模检测和分割数据集。我们的实验表明,Mask DINO 在 ResNet-50 骨干网和带有 SwinL 骨干网的预训练模型上都明显优于所有现有的专门分割方法。值得注意的是,Mask DINO 在十亿参数下的模型中,在实例分割(COCO 上的 54.5 AP)、全景分割(COCO 上的 59.4 PQ)和语义分割(ADE20K 上的 60.8 mIoU)方面取得了迄今为止最好的结果。
论文链接:https://arxiv.org/abs/2206.02777
代码链接:https://github.com/IDEA-Research/MaskDINO
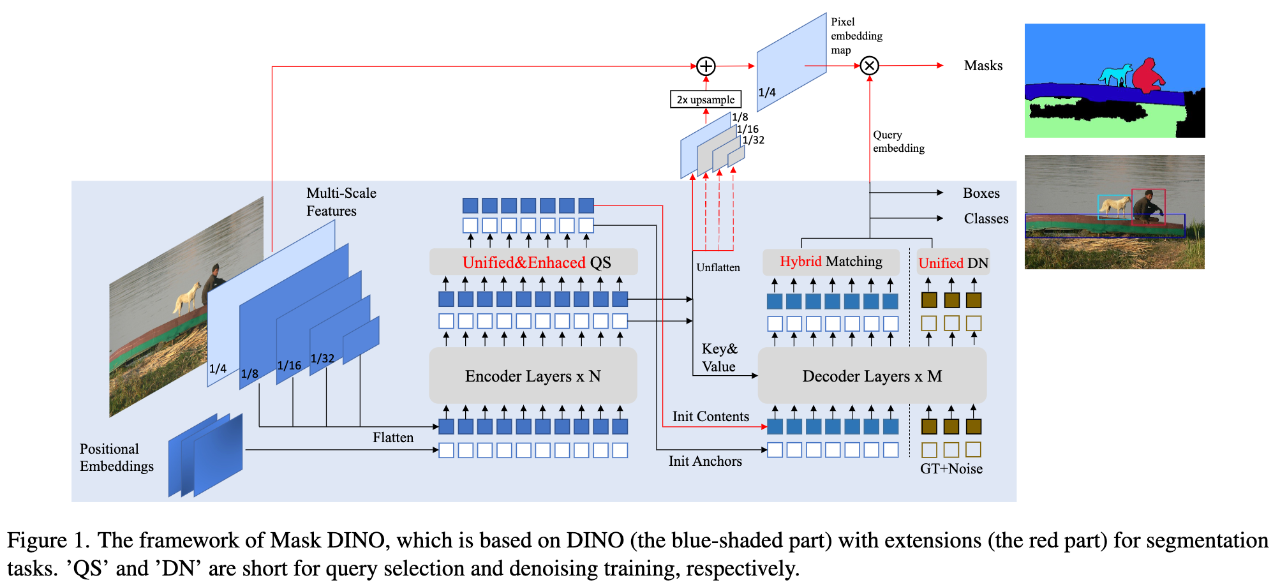

一种即插即用的图像分割方法,可以帮助基于 attention 机制的分割模型无痛涨点。
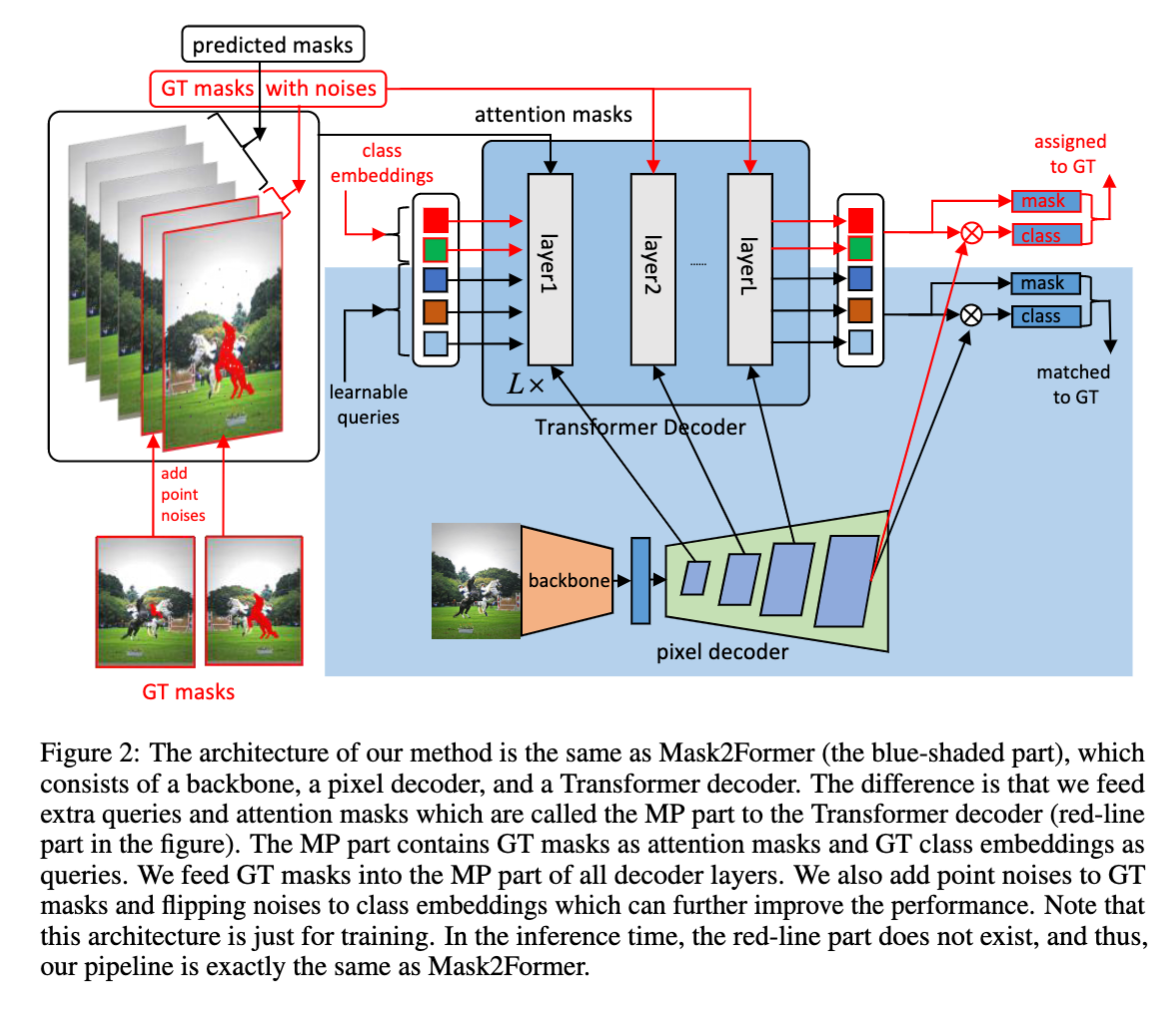
摘要:我们提出了 Mask Piloted Transformer,它改进了 Mask2Former 中用于图像分割的 maskd attention。这种改进是基于我们的观察,即 Mask2Former 受制于 decoder 层之间不一致的 mask 预测,这导致不一致的优化目标。针对这一问题,我们提出了一种 Mask Piloted 的训练方法,该方法在 mask attention 中额外提供噪声 GT masks,并训练模型来重建原始 mask。与 mask-attention 中使用的预测 mask 相比,GT mask 作为先导,有效地减轻了 Mask2Former 中不准确的 mask prediction 的负面影响。基于这种技术,我们的 MP-Former 在所有三个图像分割任务(实例、全景和语义)上实现了显著的性能改进,在带有 ResNet-50 主干的 Cityscapes 实例和语义分割任务上分别获得了+2.3AP 和+1.6mIoU。我们的方法还显著加快了训练速度,在 ADE20K 上使用 ResNet-50 和 Swin-L 主干的训练 epoch 数量是 Mask2Former 的一半。此外,我们的方法在训练过程中只引入很少的计算,在推理过程中不引入额外的计算。

首个一阶段全身人体网格重建方法 OSX,同时发布了大规模的关注真实场景的上半身 3D 全身动捕数据集 UBody。
摘要:这篇文章提出了首个用于全身(包括手,脸,身体)人体网格重建的一阶段框架 OSX。由于手、脸的分辨率问题,以往的方法均适用多阶段的裁剪-拼接方式,来进行全身人体网格重建,而本文提出了模块感知的 Transformer 模型,使用编码器来捕获全局信息,估计身体部分的参数,使用解码器聚焦于局部特征,来重建人脸和人手,实现了一阶段的全身人体网格重建。本文的方法 OSX 目前是人体重建公开榜单 AGORA 的全身姿态估计榜首。
此外,针对现有数据集为室内实验室采集数据,使得现有模型对真实应用场景缺乏泛化能力,本文总结出 15 大类潜在的应用场景(例如娱乐节目、手语、新闻播报、采访、电影、Vlog 等),提出了一个 100 万帧关注上半身这类高度截断的图片数据集 UBody,通过自研的高精度 3D 全身人体捕捉标注方案,为该数据集提供了高质量的 3D 全身(SMPLX)标注。
Ubody 高精度全身标注的展示图:


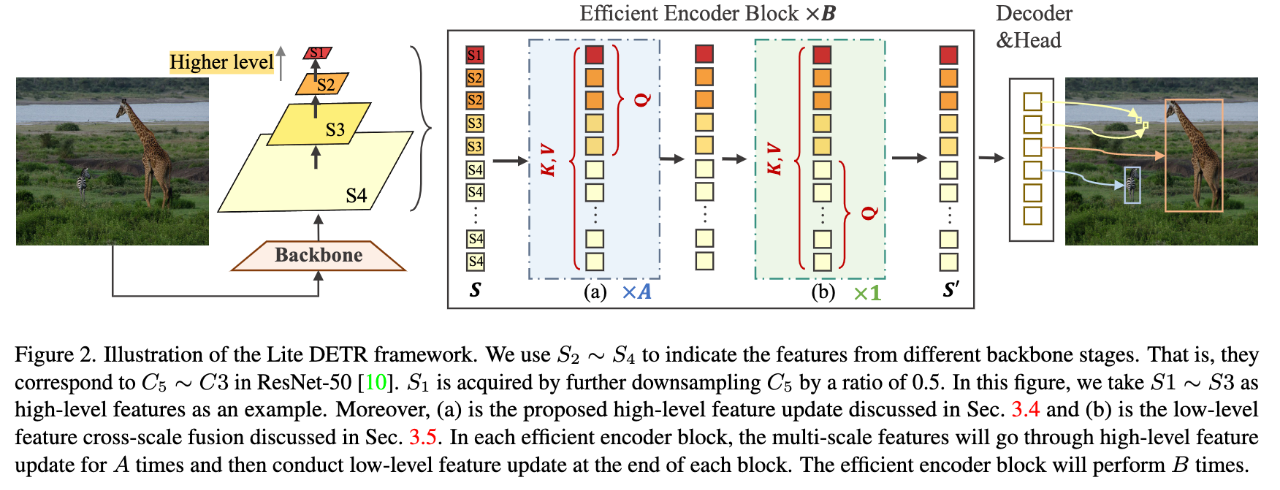
通用的高效率检测编码器,可以降低 60%编码器计算开销的同时几乎不损失性能。
摘要:最近基于检测变压器 (DETR) 的模型取得了显着的性能。新一代 DETR 检测器的成功离不开在编码器中重新引入多尺度特征融合。然而,多尺度特征中过度增加的 token,尤其是约 75%的 low-level 特征,计算效率相当低下,阻碍了 DETR 模型的实际应用。在本文中,我们提出了 Lite DETR,这是一种简单而高效的端到端目标检测框架,可以有效地将检测头的 GFLOPs 降低 60%,同时保持 99%的原始性能。具体来说,我们设计了一个高效的编码器,以交错的方式更新 high-level 特征(对应于小分辨率特征图)和 low-level 特征(对应于大分辨率特征图)。此外,为了更好地融合跨尺度特征,我们开发了一种 key-aware deformable attention 来预测更可靠的注意力权重。综合实验验证了所提出的 Lite DETR 的有效性和效率,并且高效的编码器策略可以很好地推广到现有的基于 DETR 的模型。

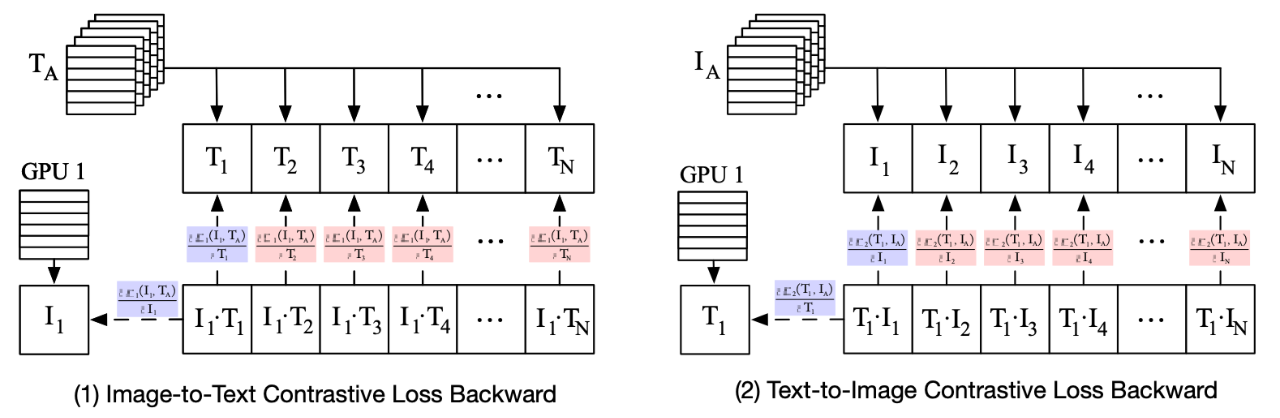
一种分布式计算对比损失的方法,降低内存消耗且不损失精度,实现 8 个 A100 40G GPU Batch Size 32K 的训练。
摘要:我们提出了 DisCo-CLIP,一种分布式内存高效的 CLIP 训练方法,以减少训练对比学习模型时对比损失的内存消耗。我们的方法将对比损失及其梯度计算分解成两个部分,一个是计算 GPU 内的梯度,另一个是计算 GPU 间的梯度。根据我们的分解,只有 GPU 内部的梯度是在当前 GPU 上计算的,而 GPU 之间的梯度是通过其他 GPU 的所有减少来收集的,而不是在每个 GPU 上重复计算。通过这种方式,我们可以将对比损失计算的 GPU 内存消耗从 O(B^2)减少到 O(B2N),其中 B 和 N 是用于训练的 Batch Size 和 GPU 的数量。这样的分布式解决方案在数学上等同于原始的非分布式对比损失计算,而不牺牲任何计算精度。它对大批量的 CLIP 训练特别有效。例如,DisCo-CLIP 可以用 8 个 A100 40GB 的 GPU 对一个 Batch Size 为 32K 的 ViT-B/32 模型进行对比训练,或者用 64 个 A100 40GB 的 GPU 对一个 Batch Size 为 196K 的模型进行训练,而原始的 CLIP 解决方案则需要 128 个 A100 40GB 的 GPU 来训练一个 Batch Size 为 32K 的 ViT-B/32 模型。

一个可用于多种以人为中心的任务的 Human-Art 数据集,衔接自然拍摄场景与人造场景。
摘要:自古以来,人类形象便以丰富多样的表现形式记录存在于艺术创作中,在照相机发明之前,油画、素描、雕塑等等都是描绘人类最主要的媒介。然而目前大多数以人为中心的计算机视觉任务,例如人体姿态检测和人类图像生成,都仅仅关注了现实世界中的真实照片,这使得对应的深度学习模型在更丰富的场景下常常会出现性能下降甚至完全失效的问题。
艺术来源于生活,却又高于生活,本文提出的 HumanArt 数据集从艺术出发连接虚拟与现实,具体来说,HumanArt 数据集收集了 5 个真实场景和 15 个虚拟场景中的 50k 张高质量图像,并为其中超过 123k 个人物标注了精准的位置框以、21 个关键点以及人体自接触点,同时,数据集提供了每张图片的文字描述,因此也可以为多场景下以人为中心的文生图模型提供性能衡量标准。
我们在论文中提供了多类下游任务上 HumanArt 的作用:
1. 2D 人体检测
2. 2D 人体姿态识别
3. 3D 人体重建
4. 多场景人体图像生成
5. 多场景人物动作迁移
同时,我们相信 HumanArt 也可以为更多研究方向(如 out-of-distribution(OOD) 问题)提供帮助,引发学术界更多的思考。

国际顶级学术会议 CVPR 2023 近日公布论文收录结果,IDEA 研究院 8 篇研究工作入选,涵盖了目标检测、图像分割等计算机视觉领域的重要任务以及多模态语义理解等领域,在 3D 人体姿态估计、轻量级模型设计、高效 CLIP 训练策略、多画风数据集等取得了新的进展。
CVPR 全称为 IEEE 国际计算机视觉与模式识别会议,在 Google Scholar 的学术会议/期刊排名中目前位列第 4。CVPR 2023 投稿论文 9155 篇中共收录 2360 篇,录取率为 25.78%,会议预计将于 6 月 18 日至 22 日在加拿大温哥华举办。
欢迎跟随本期文章,了解 IDEA 研究院在计算机视觉领域的部分最新学术成果。
统一的检测和分割框架,简洁高效,SOTA 性能。
摘要:在本文中,我们介绍了 Mask DINO,一个统一的目标检测和分割框架。Mask DINO 通过添加支持所有图像分割任务(实例、全景和语义)的分割预测分支扩展了 DINO(DETR with Improved Denoising Anchor Boxes)。它利用来自 DINO 的查询嵌入对高分辨率像素嵌入图进行点积,以预测一组二进制分割。DINO 中的一些关键组件通过共享架构和训练过程进行了扩展以进行分割。Mask DINO 简单、高效且可扩展,并且可以受益于联合大规模检测和分割数据集。我们的实验表明,Mask DINO 在 ResNet-50 骨干网和带有 SwinL 骨干网的预训练模型上都明显优于所有现有的专门分割方法。值得注意的是,Mask DINO 在十亿参数下的模型中,在实例分割(COCO 上的 54.5 AP)、全景分割(COCO 上的 59.4 PQ)和语义分割(ADE20K 上的 60.8 mIoU)方面取得了迄今为止最好的结果。
论文链接:https://arxiv.org/abs/2206.02777
代码链接:https://github.com/IDEA-Research/MaskDINO
一种即插即用的图像分割方法,可以帮助基于 attention 机制的分割模型无痛涨点。
摘要:我们提出了 Mask Piloted Transformer,它改进了 Mask2Former 中用于图像分割的 maskd attention。这种改进是基于我们的观察,即 Mask2Former 受制于 decoder 层之间不一致的 mask 预测,这导致不一致的优化目标。针对这一问题,我们提出了一种 Mask Piloted 的训练方法,该方法在 mask attention 中额外提供噪声 GT masks,并训练模型来重建原始 mask。与 mask-attention 中使用的预测 mask 相比,GT mask 作为先导,有效地减轻了 Mask2Former 中不准确的 mask prediction 的负面影响。基于这种技术,我们的 MP-Former 在所有三个图像分割任务(实例、全景和语义)上实现了显著的性能改进,在带有 ResNet-50 主干的 Cityscapes 实例和语义分割任务上分别获得了+2.3AP 和+1.6mIoU。我们的方法还显著加快了训练速度,在 ADE20K 上使用 ResNet-50 和 Swin-L 主干的训练 epoch 数量是 Mask2Former 的一半。此外,我们的方法在训练过程中只引入很少的计算,在推理过程中不引入额外的计算。
首个一阶段全身人体网格重建方法 OSX,同时发布了大规模的关注真实场景的上半身 3D 全身动捕数据集 UBody。
摘要:这篇文章提出了首个用于全身(包括手,脸,身体)人体网格重建的一阶段框架 OSX。由于手、脸的分辨率问题,以往的方法均适用多阶段的裁剪-拼接方式,来进行全身人体网格重建,而本文提出了模块感知的 Transformer 模型,使用编码器来捕获全局信息,估计身体部分的参数,使用解码器聚焦于局部特征,来重建人脸和人手,实现了一阶段的全身人体网格重建。本文的方法 OSX 目前是人体重建公开榜单 AGORA 的全身姿态估计榜首。
此外,针对现有数据集为室内实验室采集数据,使得现有模型对真实应用场景缺乏泛化能力,本文总结出 15 大类潜在的应用场景(例如娱乐节目、手语、新闻播报、采访、电影、Vlog 等),提出了一个 100 万帧关注上半身这类高度截断的图片数据集 UBody,通过自研的高精度 3D 全身人体捕捉标注方案,为该数据集提供了高质量的 3D 全身(SMPLX)标注。
Ubody 高精度全身标注的展示图:
通用的高效率检测编码器,可以降低 60%编码器计算开销的同时几乎不损失性能。
摘要:最近基于检测变压器 (DETR) 的模型取得了显着的性能。新一代 DETR 检测器的成功离不开在编码器中重新引入多尺度特征融合。然而,多尺度特征中过度增加的 token,尤其是约 75%的 low-level 特征,计算效率相当低下,阻碍了 DETR 模型的实际应用。在本文中,我们提出了 Lite DETR,这是一种简单而高效的端到端目标检测框架,可以有效地将检测头的 GFLOPs 降低 60%,同时保持 99%的原始性能。具体来说,我们设计了一个高效的编码器,以交错的方式更新 high-level 特征(对应于小分辨率特征图)和 low-level 特征(对应于大分辨率特征图)。此外,为了更好地融合跨尺度特征,我们开发了一种 key-aware deformable attention 来预测更可靠的注意力权重。综合实验验证了所提出的 Lite DETR 的有效性和效率,并且高效的编码器策略可以很好地推广到现有的基于 DETR 的模型。
一种分布式计算对比损失的方法,降低内存消耗且不损失精度,实现 8 个 A100 40G GPU Batch Size 32K 的训练。
摘要:我们提出了 DisCo-CLIP,一种分布式内存高效的 CLIP 训练方法,以减少训练对比学习模型时对比损失的内存消耗。我们的方法将对比损失及其梯度计算分解成两个部分,一个是计算 GPU 内的梯度,另一个是计算 GPU 间的梯度。根据我们的分解,只有 GPU 内部的梯度是在当前 GPU 上计算的,而 GPU 之间的梯度是通过其他 GPU 的所有减少来收集的,而不是在每个 GPU 上重复计算。通过这种方式,我们可以将对比损失计算的 GPU 内存消耗从 O(B^2)减少到 O(B2N),其中 B 和 N 是用于训练的 Batch Size 和 GPU 的数量。这样的分布式解决方案在数学上等同于原始的非分布式对比损失计算,而不牺牲任何计算精度。它对大批量的 CLIP 训练特别有效。例如,DisCo-CLIP 可以用 8 个 A100 40GB 的 GPU 对一个 Batch Size 为 32K 的 ViT-B/32 模型进行对比训练,或者用 64 个 A100 40GB 的 GPU 对一个 Batch Size 为 196K 的模型进行训练,而原始的 CLIP 解决方案则需要 128 个 A100 40GB 的 GPU 来训练一个 Batch Size 为 32K 的 ViT-B/32 模型。
一个可用于多种以人为中心的任务的 Human-Art 数据集,衔接自然拍摄场景与人造场景。
摘要:自古以来,人类形象便以丰富多样的表现形式记录存在于艺术创作中,在照相机发明之前,油画、素描、雕塑等等都是描绘人类最主要的媒介。然而目前大多数以人为中心的计算机视觉任务,例如人体姿态检测和人类图像生成,都仅仅关注了现实世界中的真实照片,这使得对应的深度学习模型在更丰富的场景下常常会出现性能下降甚至完全失效的问题。
艺术来源于生活,却又高于生活,本文提出的 HumanArt 数据集从艺术出发连接虚拟与现实,具体来说,HumanArt 数据集收集了 5 个真实场景和 15 个虚拟场景中的 50k 张高质量图像,并为其中超过 123k 个人物标注了精准的位置框以、21 个关键点以及人体自接触点,同时,数据集提供了每张图片的文字描述,因此也可以为多场景下以人为中心的文生图模型提供性能衡量标准。
我们在论文中提供了多类下游任务上 HumanArt 的作用:
1. 2D 人体检测
2. 2D 人体姿态识别
3. 3D 人体重建
4. 多场景人体图像生成
5. 多场景人物动作迁移
同时,我们相信 HumanArt 也可以为更多研究方向(如 out-of-distribution(OOD) 问题)提供帮助,引发学术界更多的思考。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

